

Strukturen sind, wie sie sind, weil das ihrem Zweck am besten dient. Das gilt für Gebäude, Brücken, Fahrzeuge, Organisationen, Organismen.
In der Natur entstehen Strukturen des Lebendigen in einem blinden, evolutionären Prozess. Was überlebt, hat eine genügend gute Struktur. Bei menschengemachten Strukturen sind Strukturen so gut, wie es nach Stand der Erkenntnisse möglich ist. Wie viel Erfolg sich damit erzielen lässt, zeigt die Anwendung.
Langlebig bzw. erfolgreich sind Strukturen, wenn Elemente und ihre Anordnung ein zweckvolles Gleichgewicht herstellen in einem Spiel von Kräften. Bei allem Materiellen sind diese Kräfte zunächst physikalisch. Gravitation, Wind, Erschütterungen, Wärme usw. wirken aus allen Richtungen. Dazu kommen bei menschengemachten materiellen Strukturen noch funktionale und nicht-funktionale Anforderungen. Sie formen durch Nachfrage an den Hersteller.
Bei Software ist das nicht anders. Software ist zwar eine nicht-materielle Struktur, doch auch sie wird durch Kräfte geformt. Kunden bzw. Anwender ziehen an ihr mit den Kräften Funktionalität und Effizienz. Sie stellen die Verhaltensanforderungen dar. Sie formen die Oberfläche von Software sowie ihre Verteilung auf Hosts, d.h. die interne Struktur.
Welche Menüpunkte und Buttons eine Benutzerschnittstelle bietet, ob die Software auf mehreren Threads läuft oder als Client und Server in mehreren Prozessen oder gar auf mehreren Maschinen… das und mehr ist eine Folge der Verhalten fordernden Kräfte.
Von selbst bringt sich Software aber natürlich nicht in eine zweckvolle Struktur, bei der diese Kräfte in Balance sind. Das geschieht nur, wenn diese Kräfte gegenüber den Softwareproduzenten auch kraftvoll auftreten. Sie müssen mit zwei Beinen und einem klaren Willen ausgestattet sein, von einem Hebel – z.B. Geld – ganz zu schweigen.
Und schließlich muss für alle Seiten klar erkennbar sein, ob sich die Strukturen in die Richtung der wirkenden Kräfte bewegen. Die Konformität muss messbar sein.
Das ist für Verhaltensanforderungen quasi per definitionem der Fall.
Doch der Kunde will mehr. Eigentlich.
Er möchte z.B. korrekte Software. Software soll bei Lieferung Verhalten fehlerfrei sein und diese Korrektheit über die Zeit und durch alle Veränderungen hindurch nicht verlieren. Was korrekt war, soll korrekt bleiben, er will Regressionssicherheit.
Er möchte auch Software, die sich weitreichend verändern lässt, er möchte Wandelbarkeit. Die Korrektur von Fehlern und die Erweiterung des Verhaltens sollen möglichst einfach sein und über die Lebenszeit der Software auch bleiben.
Korrektheit, Regressionssicherheit und Wandelbarkeit sind Kräfte, die nur eigentlich auf Software wirken, weil es ihnen an Klarheit und Messbarkeit fehlt. Deshalb weiß der Kunde auch nicht so genau, wie er sie auf die Softwareproduktion anwenden soll.
Er kann die Abwesenheit von Fehlern nur bedingt aktiv feststellen. Meist erleidet er sie nur zur Unzeit. Dann jedoch kann er sie ummünzen in Forderungen nach Funktionalität oder Effizienz.
Um die Wandelbarkeit steht es noch schlechter. Sie lässt sich „im Moment“ gar nicht messen, sondern zeigt sich nur im Verlauf längerer Zeit. Eine Forderungshöhe lässt sich hier jedoch gar nicht angeben.
Korrektheit und Regressionssicherheit üben mithin lediglich eine indirekte Kraft aus, Wandelbarkeit ist sogar nur eine sehr, sehr schwache Kraft.
Dementsprechend ist Software strukturiert. Ihre Struktur richtet sich vor allem nach Funktionalität und Effizienz, nur bedingt nach Korrektheit und Regressionssicherheit und quasi gar nicht nach Wandelbar.
Das ist auch völlig ok – wenn Software nur kurzlebig sein soll. Doch das ist tendenziell nicht der Fall. Software soll vielmehr unbestimmt lange leben, d.h. im Einsatz sein und sich auch noch an wandelnde Verhaltensanforderungen anpassen lassen.
Um das zu erreichen müssen die Kräfte Korrektheit, Regressionssicherheit und Wandelbarkeit verstärkt werden. Sie müssen gleichziehen mit Funktionalität und Effizienz. Dann wird sich eine neue, eine nachhaltige Balance in der Softwarestruktur zwischen allen Kräften einstellen.
Und wie lassen sich die Kräfte stärken? Durch Klarheit und Messbarkeit. Es muss sehr leicht erkannt werden können, ob eine Struktur ihnen folgt.
Ob eine Software der Kraft Funktionalität folgt, zeigt die Anwesenheit von Logik, die die Funktionalität liefert: „Dort stehen die Berechnungen, die aus den Eingaben in diesem Dialog die Grafik in jenem Dialog machen.“
Ob eine Software der Kraft der Effizienz folgt, zeigt die Anwesenheit von Logik und/oder ihre Verteilung auf Hosts: „Dort ist der Code für die Autorisierung.“, „Hier ist der UI-Thread und dort der Thread für die Transformation im Hintergrund, damit das UI nicht einfriert.“
Welche Strukturen zeigen an, dass den Kräften Korrektheit, Regressionssicherheit und Wandelbarkeit gedient ist?
Ja, ich meine Strukturen, die das sichtbar, fühlbar machen. Prinzipien sind geduldig. Software soll z.B. dem Single Responsibility Principle (SRP) folgen – doch wie kann ich das am Code ablesen?
Ohne hard-and-fast rules zur Strukturierung von Software sind die Nachhaltigkeitskräfte im Verhältnis zur den Verhaltenskräften schwach. Sie müssen schon ohne die zwei Beine des Kunden auskommen. Dann sollte zumindest für Entwickler glasklar sein, was zu tun ist.
[the_ad_group id=“15″]
Struktur resultierend aus der Kraft Korrektheit
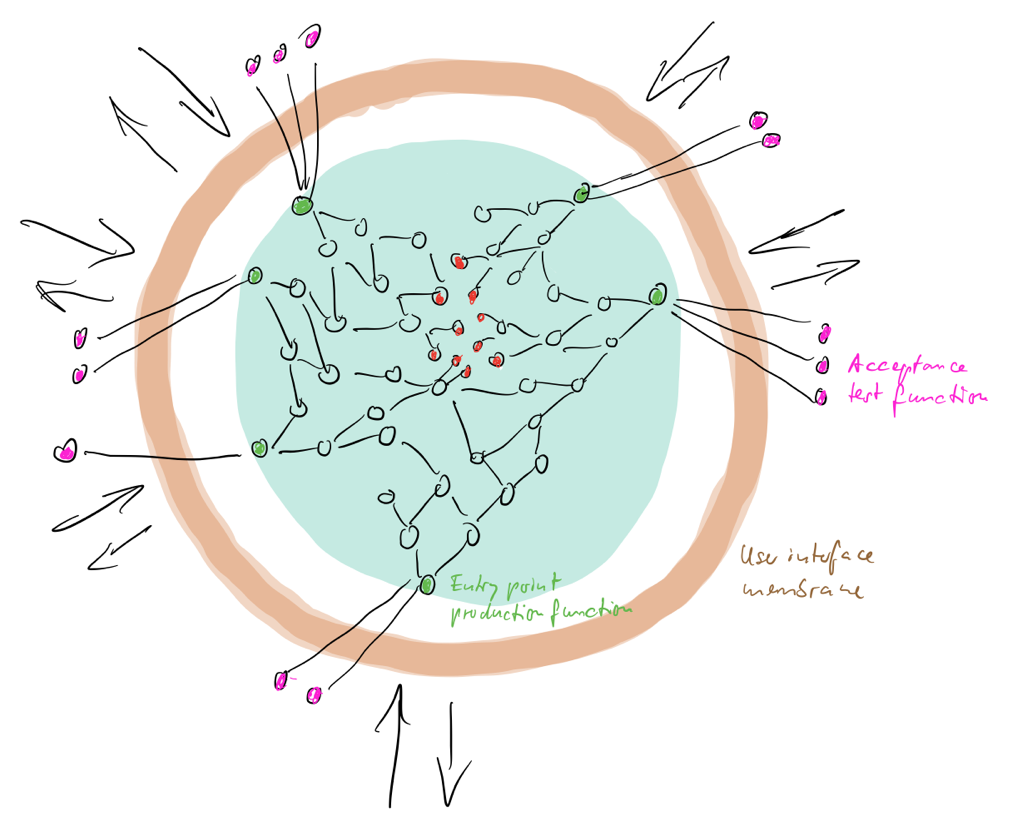
Der Kraft Korrektheit wird aus meiner Sicht mit der Ausprägung eines Paares bestehend aus Testfunktion und Produktionsfunktion entsprochen.
Die Testfunktion codiert ein Beispiel für korrektes Verhalten, wie der Kunde/Anwender es sich wünscht. Sie stellt einen Akzeptanztest dar, sie dokumentiert das Verständnis des Problems. Motto: Keine Interaktion ohne automatisierten Test!
Dem entspricht im Produktionscode genau eine Funktion, die dieses Verhalten herstellt bzw. zeigt. (Natürlich dürfen auch mehrere Testfunktionen die Produktionsfunktion „auf den Grill legen“.) Sie beschreibt einen Entrypoint in die Software. Über sie wird das Verhalten durch einen Reiz aus der Umwelt ausgelöst.
Dieses Funktionspaar erreicht zweierlei: Zum einen entsteht klare accountability. Einem geforderten Verhalten wird ein konkretes Strukturelement gegenübergestellt, das dafür verantwortlich ist. Die Produktionsfunktion hat einen syntaktischen Kontrakt über den sie eine Semantik verspricht. Beides überprüft die Testfunktion. Sie fordert das Versprechen des Produktionscodes automatisiert und damit für jeden jederzeit überprüfbar ein.
Zum anderen entsteht eine Trennung zweier grundlegender Verantwortlichkeit: Benutzerschnittstelle und Verhaltensproduktion. Die Benutzerschnittstelle stellt Verhalten nicht selbst her, sondern dient nur der Veranlassung bzw. dessen Projektion. Also sollte die Benutzerschnittstelle auch nicht für die Überprüfung korrekten Verhaltens nötig sein. Sie kann die Verifikation nur erschweren entweder durch die Notwendigkeit zur manuellen Akzeptanztests oder Mehraufwand für spezielle Testautomatisierungswerkzeuge.
Software wird durch diese simple Regel sowohl horizontal wie vertikal fundamental geteilt:
- Horizontal zerfällt Software in eine dünne Membran für das UI und einen Kern „für den Rest“.
- Vertikal wird „der Rest“ geteilt in Funktionsbäume, deren Wurzeln für die Verarbeitung einzelner Reize stehen.
Struktur resultierend aus der Kraft Regressionssicherheit
Regressionssicherheit wird zum Teil schon hergestellt durch die automatisierten Akzeptanztests. Letztlich müssen die jedoch lückenhaft bleiben. Genügend viele Ausführungspfade lediglich durch (umfangreiche) Akzeptanztests auf Produktionsfunktionen nahe der Oberfläche abdecken zu wollen, scheint mir unrealistisch.
Zusätzlich sollten deshalb alle öffentlichen Funktionen von Produktionsklassen ebenfalls mit mindestens einer Testfunktion gepaart werden. Diese Funktionen definieren Kontrakte im Inneren von Software dar. Wie die Semantik dieser Kontrakte aussieht und ob sie eingehalten wird, ist keine geringe Sache. Beides wird aber dokumentiert mit Tests.
Müssen es wirklich alle öffentlichen Funktionen von Produktionsklassen sein? Der Einfachheit halber sage ich mal Ja. So sollte der Default aussehen. So ist die Regel einfach einzuhalten und zu überprüfen.
Im Einzelfall kann man sich natürlich begründet auch dagegen entscheiden. Außerdem ist damit nicht automatisch garantiert, dass wirklich, wirklich ein lückenloses Netz gewoben wird, das Regressionen fängt.
Mir geht es jedoch nicht um die optimale Methode, auf die Kraft Regressionssicherheit zu antworten, sondern um eine pragmatische. Klarheit, Einfachheit in der Anwendung finde ich wichtig. Für mich ist daher automatisierter Test aller öffentlichen Produktionsfunktionen der Standard und eine Abweichung ist erklärungsbedürftig. Wie es um Regressionssicherheit steht, wenn der Standard anders herum lautet, können wir an den heutigen Codebasen ablesen.
Dazu kommt, dass Testfunktionen für Entrypoint-Funktionen und andere Produktionsfunktionen zuerst geschrieben werden. Das erhöht die Wahrscheinlichkeit, dass die Tests überhaupt entstehen. Das befördert aber vor allem das Verständnis für den zu schreibenden Produktionscode. Wenn ich mir zuerst einen Test ausdenken muss, überlege ich genauer, wie der Kontrakt des Produktionscodes überhaupt aussehen soll.
Das bedeutet nicht, dass es keine Iterationen geben darf. Zumindest ist jedoch der Default klar. Wieder eine Regel, deren Einhaltung leicht überprüft werden kann.

Zunächst führt das zu keiner besonderen Struktur. Es werden eben nur noch weitere Produktionsfunktionen mit einem Test versehen. Das ändert sich jedoch, wenn man die Regel umkehrt: Wenn etwas „testwürdig“ ist, wenn ein Verhaltensaspekt sehr gezielt dokumentiert werden soll, dann müssen die zugehörigen Funktionen public gemacht werden. Und da deshalb bestehende Kontrakte nicht „verwässert“ werden sollten, führt das zur Entstehung weiterer Klassen.
Struktur resultierend aus der Kraft Wandelbarkeit
Auf die Kräfte Korrektheit und Regressionssicherheit lautet die Antwort Testfunktion. Auf die Kraft Wandelbarkeit jedoch lautet die Antwort „nur“ Testbarkeit.
Bei Korrektheit und Regressionssicherheit sichern die Testfunktionen zu, dass Verhalten existiert und sich nicht verändert. Sie sind Ausdruck dessen, was schon ist. Bei Wandelbarkeit hingegen geht es um ein Potenzial. Das braucht zwar eine Struktur, doch das kann nicht zur Laufzeit überprüft werden.
Wenn ich mir die Prinzipien für Clean Code anschaue, dann scheinen mir zwei zentral: DRY und HCLC (High Cohesion, Low Coupling). Doch zu welchen Strukturen führen die? Kann ich die Einhaltung an ihrer Form erkennen?
Man kann über diese Prinzipien und andere lange, lange nachdenken und diskutieren. Man kann sich daran richtig einen Wolf entwerfen oder refaktorisieren. Dann ist das Ergebnis vielleicht auch perfekt – nur ist das ein langsamer Prozess. Außerdem klingt das sehr kompliziert. Viel, viel Erfahrung ist nötig, um die besten ausbalancierten Entscheidungen zu treffen, oder? Wer traut sich das schon im Sperrfeuer des Alltags zu?
Diese ganze Prinzipienreiterei hört sich für mich zunehmend an wie scholastische Disputation im Mittelalter. Total interessant, nur wenig praxistauglich. Deshalb findet Clean Code Development auch so selten statt. Es scheint zu sophisticated, nichts für normalsterbliche Entwickler. Schön zum Anschauen auf Youtube und in Blogs, aber nicht zum Anwenden in der eigenen Praxis.
Wir sollten es deshalb aufgeben, perfekten Clean Code zu produzieren. Wir sollten auch aufhören, ein schlechtes Gewissen zu haben, wenn wir keinen perfekten Clean Code hinbekommen. Stattdessen lieber eine realistische, pragmatische Haltung einnehmen. Hard-and-fast rules, um jederzeit das halbwegs Richtige zu tun. Wenn dann irgendwann nochmal Zeit ist, kann man ja nachjustieren, abschleifen und polieren.
Für mich stehen deshalb zwei ganz, ganz einfache Regeln zur Herstellung von Wandelbarkeit am Anfang:
- Produktionsfunktionen enthalten entweder Logik und rufen keine anderen Produktionsfunktionen auf; dann heißen sie Operationen. Oder sie rufen ausschließlich Produktionsfunktionen auf und enthalten keine Logik; dann heißen sie Integrationen. Ich nenne das mal the Integration Operation Segregation Rule (IOSR).
- Außerdem sollen Produktionsfunktionen – Operationen wie Integrationen – nicht wissen, woher ihr Input kommt und wohin ihr Output fließt. Sie sollen ihre Umgebung nicht beachten. Ich nenne das malthe Rule of Mutual Oblivion (RoMO).
Bei Anwendung dieser Regeln entstehen Funktionsbäume, die speziell sind und sich sehr von denen unterscheiden, die Sie in Ihrer Codebasis finden. In diesen Bäumen existiert Logik nämlich nur in den Blättern – während sie üblicherweise über die ganze Tiefe von Funktionsbäumen verschmiert ist.
Logik in den Blättern hat nun jedoch einen entscheidenden Vorteil: sie ist wunderbar einfach testbar. Sie hängt ja nicht mehr von anderer Logik ab. Die Blätter sind Operationen, darüber liegen potenziell viele Strata von Integrationen.

Das bedeutet, es sind keine Testattrappen mehr nötig, um Logik zu überprüfen. Und das wiederum führt dazu, dass Overhead durch Dependency Inversion und Dependency Injection reduziert wird.
Aber Achtung: Es geht nur um Testbarkeit. Alle Operationen sollten zwar testgestützt implementiert werden. Doch nach Fertigstellung sollten diese Tests in den Papierkorb wandern, sofern die Operationen keine öffentlichen Produktionsfunktionen sind. Die Tests sind lediglich Gerüste für eine korrekte Implementation im Kleinen und somit temporär. Auf lange Sicht wird die Korrektheit durch Regressions- und Korrektheitstests zugesichert, die bis in die Operationen wirken. Zusätzliche Tests würden die Wandelbarkeit einschränken. Das bedeutet auch, dass private Operationen privat bleiben sollen, selbst wenn sie kurzzeitig für Gerüsttests öffentlich gemacht werden müssen.
Wie gesagt: Es geht bei der Wandelbarkeit nur um Testbarkeit, nicht um dauerhafte Existenz von Tests. Bei Bedarf soll es einfach sein, Tests für Logik-Aspekte jeder Granularität aufzusetzen.
Grundsätzlich sehr gute Testbarkeit ergibt sich durch Befolgung der Regeln IOSR und RoMO. Sie sorgen dafür, dass Produktionsfunktionen ganz von allein vergleichsweise klein bleiben. Die Logik in Operationen ist viel fokussierter als in üblichen Codebasen, weil IOSR verhindert, dass Request/Response-Aufrufe zwischengeschaltet werden.
Dennoch können Operationen „schlecht geschnitten“ sein oder mehrere Verantwortlichkeiten enthalten. Das zu beurteilen, ist jedoch aufgrund der Form kaum möglich. Solch inhaltlichen Aspekte sind Sache des domänenkundigen Betrachters.
Aber es gibt weitere Indizien für gute Testbarkeit:
- Zustandslosigkeit
- Unabhängigkeit von externen Ressourcen, z.B. Datenbank, TCP-Verbindung, UI-Framework
Das bedeutet im Umkehrschluss: Abhängigkeiten von Zustand bzw. externen Ressourcen, die zentral für jede Software sind und sich nicht wegdiskutieren lassen, sollten wenigstens in eigenen Produktionsfunktionen gebündelt werden.
Nicht nur führt IOSR also zu einer vertikalen Strukturierung und RoMO zu einer horizontalen Entkopplung einhergehend mit kleinen Funktionen, es werden auch noch weitere Funktionen „ausgetrieben“ durch Trennung grundsätzlicher formaler Aspekte. Ich nenne das mal the Rule of Separating Concerns (RoSC).
Strukturen abstrahieren
Bisher habe ich nur von Produktionscodefunktionen gesprochen. Was ist aber mit Klassen und den darüber liegenden Modulebenen? Sie entstehen für mich durch rigorose Abstraktion.
Wenn Funktionen die ersten Strukturelemente sind, um auf die Kräfte Korrektheit, Regressionssicherheit und Wandelbarkeit zu reagieren, dann entsteht eine Menge, in der sich Muster erkennen lassen. Diese Muster sind für mich die Grundlage für die Zusammenfassung von Funktionen in Klassen. Klassen abstrahieren von den konkreten Funktionen; sie geben Mustern einen Namen.
Hier werden ein paar Funktionen zusammengefasst, die mit den selben Daten arbeiten, dort einige, die den selben API nutzen, da drüben welche, die sich um den selben Domänenaspekt kümmern usw. usf.
Das ist für mich „Objektorientierung von unten“. Es stehen nicht Klassen und Objekte am Anfang, sondern Funktionen. Softwarestruktur wird damit durch Verhalten getrieben und nicht durch Daten.
***
Clean Code ist notwendig. Je länger eine Codebasis leben soll, desto wichtiger wird es, nachhaltig mit ihr umzugehen. Das Gefühl muss über die dominanten Kräfte Funktionalität und Effizienz hinaus reichen; Sensibilität für Korrektheit, Regressionssicherheit und Wandelbarkeit muss entstehen.
Doch diese Kräfte sind immer schwächer als Funktionalität und Effizienz. Wer das kompensieren will, wer eine differenziertere, eine zukunftsfähigere Balance herstellen will, der braucht hard-and-fast rules, die auch mit Tunnelblick unter Stress noch angewandt werden können. Das Resultat muss dann nicht perfekter Clean Code sein, aber deutlich besserer als heute.
Mit den vorgestellten Regeln ist das aus meiner Sicht möglich. Auch die brauchen noch Disziplin und Übung, doch sie sind viel, viel klarer als die ewig zitierten Prinzipien des Clean Code.
Wenn ich meine Empfehlung zur Reaktion auf die Kräfte Korrektheit und Regressionssicherheit noch zusammenfasse zu Test-first All Contracts Rule (TfACR), dann lautet die Zusammenfassung:
- TfACR
- IOSR
- RoMO
- RoSC
Durch diese Regeln, so glaube ich, entstehen Softwaresysteme, die eine deutlich saubere Grundstruktur haben.
Und jetzt: Nicht lang schnacken, Kopf in Nacken :-) Wie wir in Norddeutschland sagen. Machen, statt reden. Engage!