

Die beiden wesentlichen Prinzipien für Clean Code Development sind für uns das IOSP und das PoMO.
An
version of this article is available here.
- Nach dem Integration Operation Segregation Principle (IOSP) sollen Funktionen (oder allgemeiner: Module) ihre Grundverantwortlichkeit entweder auf die Herstellung von Verhalten durch Logik konzentrieren (Operation) oder selbst keine Logik enthalten, sondern nur andere Module zu einer größeren Einheit integrieren.
- Das Principle of Mutual Oblivion (PoMO) hingegen sorgt für Entkopplung von Funktionen (oder allgemeiner: Modulen), die zusammen einen Gesamtzweck verfolgen. Sie sollen einander nicht kennen, sondern lediglich über Nachrichten anonym und unidirektional in Verbindung stehen. Die Verschaltung zu einem Netzwerk übernimmt eine integrierende Einheit.
Diese Prinzipien sind klar und einfach und führen zu Code, der einige günstige Eigenschaften besitzt, z.B.:
- Funktionen haben nur einen geringen Umfang.
- Funktionen sind quasi selbstverständlich auf eine inhaltliche Aufgabe konzentriert.
- Funktionen sind nicht funktional von einander abhängig. Das macht sie leicht testbar.
- Integrationen bieten natürliche Ansatzpunkte für Erweiterungen, ohne bestehende Logik verändern zu müssen.
- Integrationen geben in leicht lesbarer Form das Was von Code wieder.
Integration ohne Logik
Allerdings stößt die Befolgung dieser Prinzipien immer wieder auf Widerstände, weil es schwierig oder gar unmöglich scheint, Logik komplett aus Integrationen herauszuhalten. Wie soll z.B. dieser Entwurf umgesetzt werden?
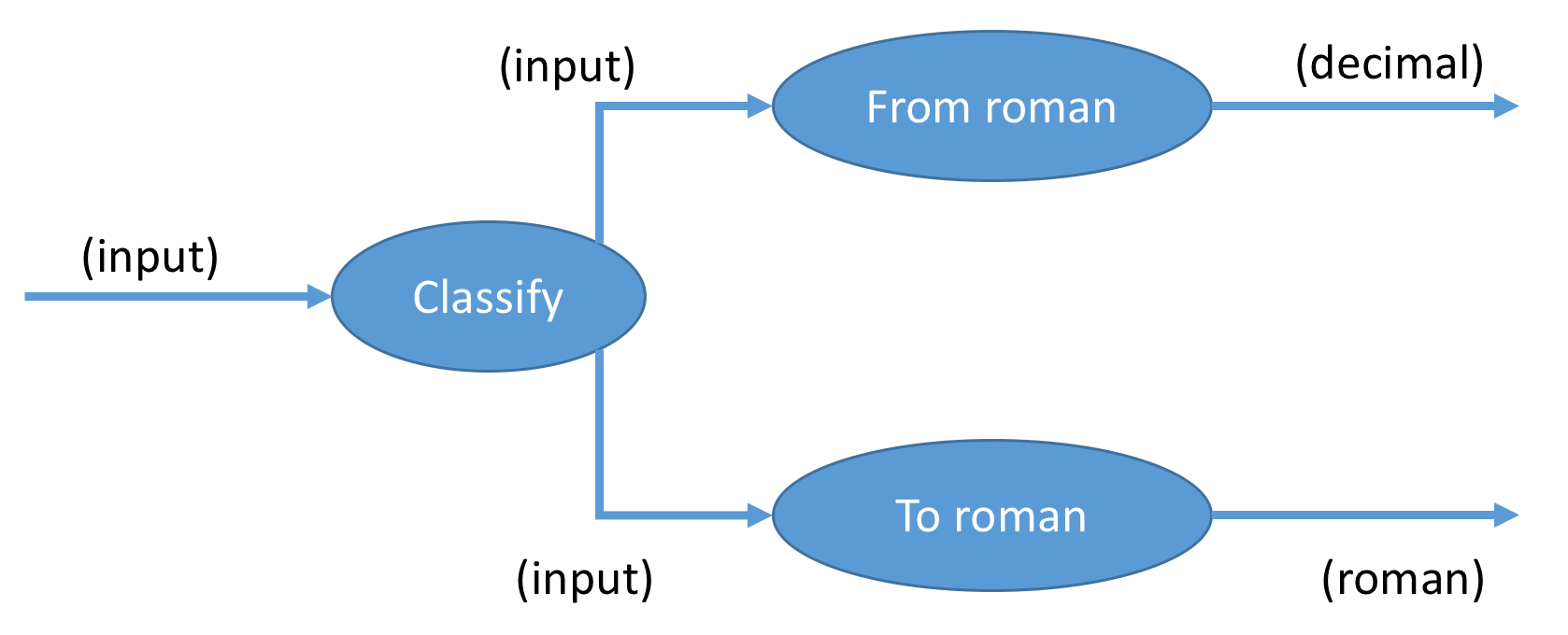
Eine Eingabe, die entweder eine römische Zahl oder eine Dezimalzahl ist, soll in die jeweils andere Zahlendarstellung übersetzt werden. Dazu ist doch eine Fallunterscheidung nötig. Die naheliegende Übersetzung wäre:
int d;
if (int.TryParse(input, out d))
{
var roman = To_roman(input);
//...
}
else {
var @decimal = From_roman(input);
//...
}Dieser Code integriert To_roman() und From_roman(), aber er enthält auch Logik: die if-else-Anweisung und die konkrete Transformation des Input in einen bool-Wert.
Das widerspricht jedoch leider dem IOSP. Nur wie sollte es sonst aussehen?
Um die Integration konsequent frei von Logik zu halten, sollte so verfahren werden:
Classify(input,
() => {
var roman = To_roman(input);
//...
},
() => {
var @decimal = From_roman(input);
//...
});Jetzt findet nur noch Integration statt. Die komplette Entscheidungslogik ist in Classify() gekapselt. Wie festgestellt wird, ob eine Dezimalzahl oder eine römische anliegt, ist nicht mehr zu sehen.
Das technische Mittel hinter dieser Übersetzung sind Funktionszeiger, die als Continuation eingesetzt werden:
void Classify(string input, Action onDecimal, Action onRoman) {
int d;
if (int.TryParse(input, out d))
onDecimal();
else
onRoman();
}
Nicht nur dient diese Funktion der Einhaltung des IOSP, sie zeigt auch PoMO-Konformität: indem die Parameternamen für die Continuations auf die Funktion selbst, also nach innen bezogen sind, wird keine Annahme darüber gemacht, was mit den Daten passiert, die über sie hinausfließen. Die Funktion hat kein Wissen über einen eventuellen Downstream ab ihrer Position in einem Verarbeitungsfluss.
Aber auch wenn auf diese Weise sehr flexibel Teilungen im Datenfluss oder mehrfache oder verzögerte Output-Lieferungen einer Funktionseinheit möglich sind… sie erweist sich stets als gewöhnungsbedürftig.
Gerade dem Clean Code Neuling stellt sich daher die Frage: Ist denn diese Art der Übersetzung wirklich alternativlos, wenn man das IOSP einhalten will? Darf in einer Integration wirklich, wirklich gar keine Logik stehen?
[the_ad_group id=“15″]
Integration mit Kontrollstrukturen
Ja, wir sind der Meinung, dass Integration vollständig ohne Logik gedacht und implementiert werden sollte. Zumindest zunächst. Zur Übung. Um sich dem Imperativen, dem Kontrollflussdenken zu entwöhnen, das der Objektorientierung unterliegt. Denn mit Kontrollflüssen lassen sich keine Lösungen planen. Die Darstellung von Kontrollflüssen „skaliert nicht“. Sie greift auch zu schnell auf globalen Zustand zurück und erzeugt Abhängigkeiten.
Am Ende jedoch liegt es uns fern, ein Dogma in die Welt zu stellen. Alles sollte mit Augenmaß und moderat betrieben werden, auch die Einhaltung von klaren Prinzipien. Solange dem Zweck gedient ist, ist auch Logik in Integrationen erlaubt. Und was ist der Zweck?
- Leichte Verständlichkeit
- Leichte Testbarkeit
- Hohe Wandelbarkeit
Fallunterscheidungen
Hier ein erster Vorschlag zur Güte mit Logik in der Integration zum obigen Beispiel:
if (Is_decimal(input))
{
var roman = To_roman(input);
//...
}
else {
var @decimal = From_roman(input);
//...
}
Die Integration enthält immer noch if-else als Kontrollstruktur, doch das Wie der Entscheidung ist ausgelagert in die Funktion Is_decimal(). Die ist wieder gut testbar.
Allerdings weicht der Name der entscheidenden Funktion nun vom Entwurf ab. Das ist dem Rückgabewert geschuldet. Da die Wahl auf bool gefallen ist zur Unterscheidung der beiden Zahlenarten, passt Classify() als Funktionsname nicht gut; if (Classify(input)) liest sich nicht flüssig.
Natürlich ist die Verwendung von bool als Rückgabetyp ok, doch dann sollte der Entwurf anders aussehen. Schon dort sollte „Is decimal?“ als Bezeichnung für die Funktionseinheit gewählt werden, die die Zahlenart prüft.
Einerseits. Denn andererseits sollte ein Datenfluss eben Datenfluss sein und nicht Kontrollfluss. Ein if jedoch ist die grundlegende Anweisung in Kontrollflüssen. Es ist direkt vom bedingten Sprung des Maschinencodes abgeleitet.
Die Bezeichnung „Classify“ im obigen Entwurf war also schon mit Bedacht gewählt. Denn darum geht es: eine Klassifikation, aufgrund derer die Verarbeitung unterschiedlich weiter fließt.
Wenn dieser Name beibehalten werden soll, wie könnte dann dafür eine Übersetzung aussehen? Ich schlage vor, eine Aufteilung des Datenflusses allgemein mit einem enum-Datentyp anzuzeigen:
enum NumberCategories {
Decimal,
Roman
}
NumberCategories Classify(string input)
{
int d;
if (int.TryParse(input, out d))
return NumberCategories.Decimal;
return NumberCategories.Roman;
}
Aus dem if-else wird dann ein switch:
switch (Classify(input))
{
case NumberCategories.Decimal:
var roman = To_roman(input);
//...
break;
case NumberCategories.Roman:
var @decimal = From_roman(input);
//...
break;
}
Das sieht ähnlich der Lösung mit den Continuations aus, oder? Es ist sogar ein wenig besser lesbar, da für jeden Ast des Datenflusses klar ist, um welchen es sich handelt.
Ist Logik in der Integration also doch eine gute Sache und erlaubt? Jein. So, wie hier angewandt, ist sie unschädlich, gar hilfreich. Doch unbedacht angewandt, öffnet sie Tür und Tor zu schlechter Lesbarkeit und schlechter Testbarkeit.
So auch hier: Es lässt sich zwar leicht testen, ob Classify() seine Sache korrekt macht. Aber wird das Ergebnis dann auch korrekt weiterverarbeitet? Gibt es einen Fall für jeden Wert des enum? Der C#-Compiler stellt das nicht sicher. Um die Abdeckung zu prüfen, müsste also im Zweifelsfall die switch-Logik in der Integration getestet werden – mit all dem, was daran hängt. Die Testbarkeit des Codes ist damit geringer, als würde das switch (oder ein if) in Classify gekapselt sein.
Schleifen
Wie viel Logik ist denn nun aber erlaubt? Bevor ich die Frage beantworte, lassen Sie uns noch auf die Schleifen als Kontrollstrukturen schauen.
In Datenflüssen werden häufig Mengen von Daten übermittelt. Hier ein Beispiel:

Aus einer Pfadangabe werden viele Dateien, die jede in ein Resultat zu überführen sind. Dass nicht nur ein Datum fließt, sondern eine Collection von Daten, zeigt der * hinter der Datenbezeichnung in der Klammer an.
Wenn die Verarbeitung pro file einfach ist, dann ist Process_files() eine Operation, z.B.
IEnumerable<int> Process_files(IEnumerable<string[]> files) {
foreach (var f in files)
yield return f.Length;
}
Doch was, wenn die Arbeit auf dem Dateiinhalt umfangreicher ist? Dann wäre es doch angezeigt, die in eine eigene Funktion auszulagern, oder? Das jedoch würde zu einem Aufruf dieser Methode in Process_files() führen, wo schon eine Kontrollstruktur steht. Ein Widerspruch zum IOSP.
IEnumerable<int> Process_files(IEnumerable<string[]> files) {
foreach (var f in files)
yield return Process_file(f);
}
Eigentlich. Denn dieser Code ist gut lesbar. Warum sollte er also nicht erlaubt sein? Die Testbarkeit ist nicht geringer geworden. Denn dass ein foreach falsch angewandt wird, ist eher nicht zu erwarten. Also kann sich ein Test auf die Operation konzentrieren, die sich mit einem file befasst: Process_file.
Die Kombination aus „Pluralfunktion“ und „Singularfunktion“ ist typisch für Implementationen von Datenflussentwürfen. Im Entwurf steht nur die Verarbeitung einer Collection, im Code wird das jedoch mit einer Funktion für diese Funktionseinheit plus einer weiteren zur Verarbeitung eines einzelnen Collection-Elements realisiert: Process_files() + Process_file().
Und wie steht es dann mit for()– und while()-Schleifen?
Wir raten davon ab!
Eine for-Schleife sieht unschuldig aus:
IEnumerable<int> Process_files(string[][] files) {
for (var i = 0; i < files.Length; i++)
yield return Process_file(files[i]);
}
Doch im Gegensatz zu einer foreach-Schleife steckt hier Logik drin und kann auch nicht weiter versteckt werden. Ist es korrekt, bei Index 0 zu beginnen? Ist die Bedingung i < files.Length korrekt? Soll wirklich nach jeder Runde der Index um 1 hochgezählt werden? Und wenn ja, wird das auch so getan?
In diesem Fall ist die Logik der Schleife simpel, doch das kann sich schnell ändern. Wie testen Sie dann, ob sie (noch) korrekt ist? Das ist isoliert nicht möglich wie beim switch mit seinen Fällen.
Während beim switch jedoch Zählen hilft, ob alle enum-Werte mit einem Fall bedacht sind, ist die Analyse der Logik einer for-Schleife nicht so einfach. Also: Finger weg von for-Schleifen in Integrationen! Sie sind zu wenig deklarativ.
Dasselbe gilt für while-Schleifen, allerdings aus anderem Grund. Schauen Sie hier:
IEnumerable<int> Process_files(Queue<string[]> files) {
var total = 0;
while (total < MAX) {
var f = files.Dequeue();
var result = Process_file(f);
yield return result;
total += result;
}
}
Spüren Sie es auch: Das ist viel weniger übersichtlich. Selbst die for-Schleife mit ihrer Logik war besser verständlich.
Immer noch wird ein Dateiinhalt verarbeitet und das Resultat zurückgegeben. Doch drumherum passiert einiges an Logik, das der while-Schleife dient. Nicht nur steht bei while ein Vergleich, es muss auch noch eine Hilfsvariable deklariert und aktualisiert werden. Deshalb auch das explizite result. (Die Queue<> als Quelle habe ich nur gewählt, um nicht noch weitere Logik zu brauchen, um auf die einzelnen Dateiinhalte zuzugreifen. Sie hat ansonsten keine Bedeutung.)
Beim while steckt die Logik nicht nur in einer Klammer, sondern verteilt sich über die ganze Schleife. Die Verantwortlichkeit ist verschmiert und vermischt mit der Integration. Sie zu verstehen, ist nicht auf einen Blick möglich, von der Testbarkeit ganz zu schweigen.
Das lässt sich auch nicht heilen, indem die Schleifenbedingung wie beim if in eine eigene Funktion ausgelagert wird. Es braucht weiterhin Zustand, der während der Schleife aktualisiert wird. Also: Finger weg von while-Schleifen in Integrationen.
Und wie sollte das obige Szenario stattdessen aussehen? Eine while-Schleife kann natürlich zum Einsatz kommen – allerdings nur in einer Operation.
IEnumerable<int> Process_files(IEnumerable<string[]> files) {
var results = Calculate(files);
return Limit(results);
}
IEnumerable<int> Calculate(IEnumerable<string[]> files) {
foreach (var f in files)
yield return Process_file(f);
}
IEnumerable<int> Limit(IEnumerable<int> results) {
var q = new Queue<int>(results);
var total = 0;
while (total < MAX) {
var result = q.Dequeue();
yield return result;
total += result;
}
}
In der Integration Process_files() findet nun wirklich nur Integration statt; jegliche Logik ist verschwunden. Calculate() ist fokussiert auf die Berechnung der Resultate. Und die Schleife ist nach Limit() ausgelagert. Dort wird nun jedoch keine weitere Produktionsfunktion mehr aufgerufen. Limit() enthält ausschließlich Logik, sie ist eine Operation.
Bitte beachten Sie, wie der Wunsch, das IOSP einzuhalten, dazu geführt hat, dass die Verantwortlichkeit, die in der while-Schleife steckte, nun freigestellt und mit einem Namen versehen ist. Es geht um eine Begrenzung der Zahl der Resultate. Das war vorher nur durch umständliche Interpretation erahnbar, als Logik und Integration noch vermischt waren.
Da die Operation Limit() ohne funktionale Abhängigkeiten gut testbar ist, können Sie sich jetzt auch leichter entscheiden, sie umzuschreiben. Vielleicht gefällt Ihnen das while nicht und sie wollen stattdessen ein foreach mit einem if darin für vorzeitigen Abbruch?
Rekursion
Schleifen lassen sich durch Rekursionen ersetzen und umgekehrt. Deshalb ist auch ein Wort nötig zur Verwendung von Logik in rekursiven integrierenden Funktionen.
Rekursionen müssen abgebrochen werden. Irgendwo ist eine Fallunterscheidung nötig, das ist Logik. Wird jedoch nicht abgebrochen, dann erfolgt der Aufruf einer Funktion, das ist Integration. Rekursionen erfordern daher zwangsläufig eine Mischung aus Logik und Integration.
Wenn die Abbruchentscheidung jedoch deutlich sichtbar z.B. am Anfang der integrierenden Methode steht, ist dagegen nichts auszusetzen. Verständlichkeit und Testbarkeit leiden nicht.
IEnumerable<int> Process_files(IEnumerable<string[]> files) {
return Process_files(new List<int>(), files);
}
List<int> Process_files(List<int> results, IEnumerable<string[]> files) {
if (files.Count() == 0) return results;
results.Add(Process_file(files.First()));
return Process_files(results, files.Skip(1));
}
Die rekursive Variante von Process_files() enthält zwei integrierende Schritte. Dass davor noch eine Zeile für die Abbruchbedingung steht, behindert die Verständlichkeit nicht. Aber natürlich gilt auch hier: Die Logik der Abbruchbedingung sollte für sich testbar sein (oder trivial wie im obigen Fall).
Empfehlungen
Wie sollten Sie mit Logik in Integrationen verfahren? Die Empfehlung lautet weiterhin: Halten Sie Integrationen frei von Logik!
Wenn Sie aber gar keinen Ausweg mehr sehen oder die Alternative wirklich nicht einfach zu lesen ist, dann beherzigen Sie Folgendes in der Integration:
- Benutzen Sie nur
foreachund nicht (!)foroderwhileals Schleifen. - Benutzen Sie
ifnur mit einer eigenen Funktion für die Bedingung. - Benutzen Sie
switchnur mit einer eigenen Funktion für die Fallbestimmung und liefern Sie aus der einenenum-Wert zurück. - In einer Rekursion machen Sie die Abbruchbedingung so knapp wie möglich (s.o.
ifbzw.switch). - Benutzen Sie pro Integration höchstens eine Kontrollanweisung.
- Schachteln Sie in Integrationen keine Kontrollanweisungen.
Das sind wirklich gut gemeinte Ratschläge. Sie sollen Ihnen helfen, dem Prinzip IOSP möglichst treu bleiben zu können.
Doch am Ende ist das Problem mit allen Empfehlungen, dass sie entweder zu Widersprüchen führen oder in sklavischer Anwendung das Gegenteil von dem erzeugen, was beabsichtigt war.
Deshalb zum Schluss noch einmal: Setzen Sie programmiersprachliche Mittel ein, wie Sie wollen. Nur überprüfen Sie immer wieder, ob Verständlichkeit und Wandelbarkeit hoch gehalten werden. Die Idee hinter IOSP (und PoMO) ist, dass durch die Abwesenheit von funktionalen Abhängigkeiten ein Datenfluss entsteht, der sowohl das gewünschte Verhalten zeigt wie auch die genannten nicht-funktionalen Anforderungen erfüllt. Das ist es wert, auch ab und an mal eine ungewohnte Codeformulierung in Kauf zu nehmen.