

Analysis drives the structure of the solution for the Diamond-Square algorithm from the outside. It defines a syntactic – and semantic – overall contract for the whole. It thus already shapes the code without much creative effort from my side. And it produces criteria to assess if the desired behavior has been achieved.
Before I start coding, though, I like to look deeper. Is there more I can glean from the specs in terms of solution structure? Are there special terms or structures or features which are characteristic to the problem domain and thus should be made explicit in code?
I believe you should manifest insights, aspects, particular problems, noteworthy decisions very clearly in code. Make them public and easy to see for everybody (I mean yourself and your fellow developers). They should not be swept under the rug as implementation details.
So far that thinking has lead to the Terrain class and visible random number generation. The algorithm is not just about behavior. It’s equally about a data structure, and a special one for that matter. And since the use of random numbers make the core function Interpolate() hard to test, they need to be made explicit, too.
Data structures
But are there further notable structures spoken about in the specs? Yes, I think so. They are even right in the title. There are squares and there are diamonds. That’s geometrical shapes. Look here:
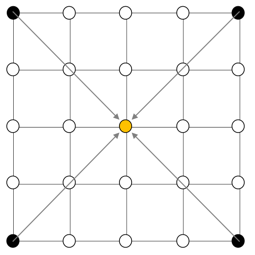
The square is defined by its center (orange) and its four vertexes (black). The same goes for a diamond (4 of them in this picture):
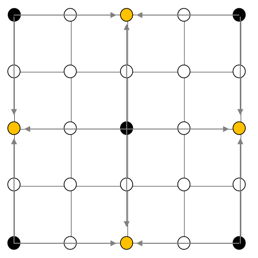
This, to me, begs for representation in code. If I was presented with code solving this problem, I’d look for such kind of structures. At least a Shape class seems in order, e.g.
class Shape {
public Coordinate Center;
public Coordinate[] Vertexes;
}
struct Coordinate {
public Coordinate(int y, int x) { Y = y; X = x; }
public int Y, X;
}
Whether there should also be subclasses Square : Shape and Diamond : Shape, I doubt. The difference between a square and a diamond is not in it’s basic structure (center, 4 vertexes), but how the structure is filled (see below).
Also, what I read in the specs is that there is a hierarchy. Shapes don’t stand alone, but are nested. Can you see that, too?
In a 5×5 matrix like depicted in the Wikipedia article I see two nested levels.
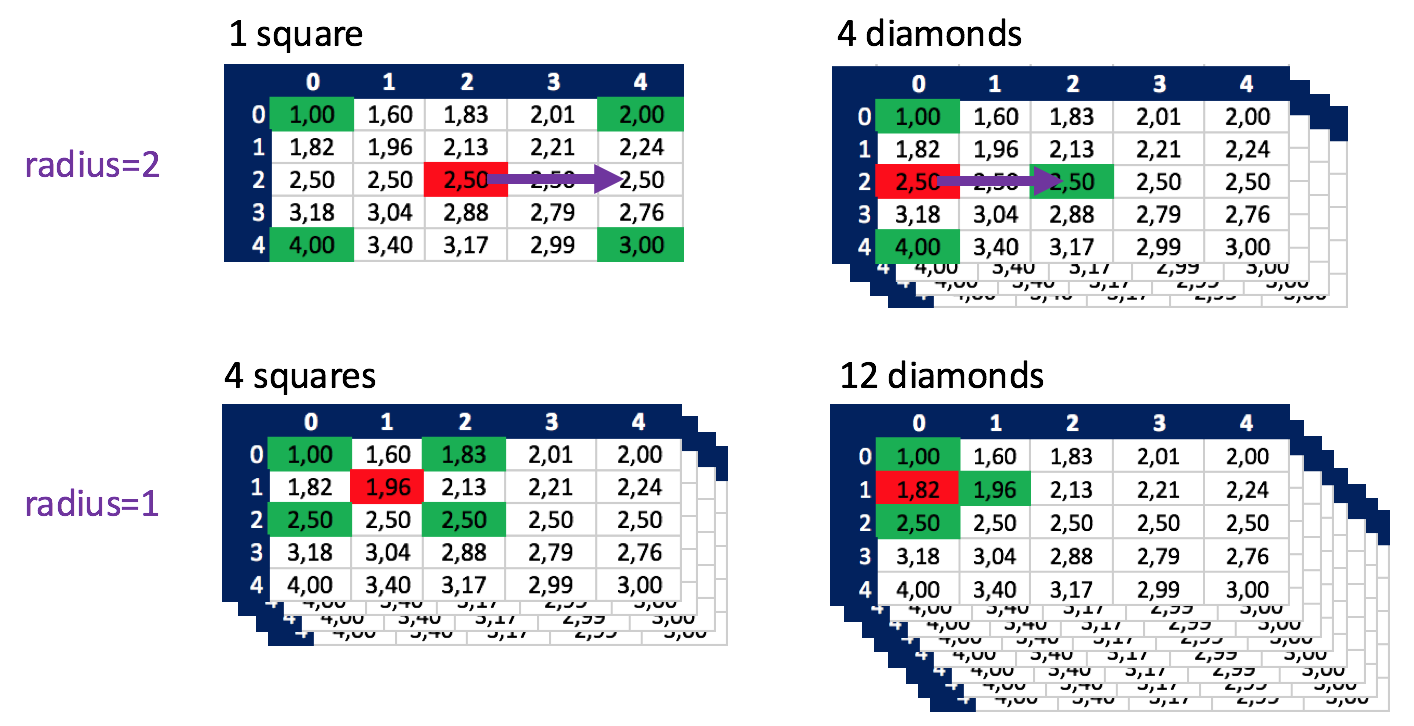
On each level there are squares and diamonds with a certain „radius“. The radius starts with 2^(n-1) and is divided by 2 with each level (for a matrix with a size of 2^n+1). Squares are nested within squares, diamonds are nested within diamonds, if you will.
For me this should be represented in code with a dedicated data structure, e.g. ShapeHierarchy. Its purpose is to represent all shapes a terrain is made up of so I can iterate over them. I deem that a responsibility of its own which should be encapsulated in a dedicated module.
class ShapeHierarchy {
int n;
public ShapeHierarchy(int n) { this.n = n; }
public IEnumerable<Shape> Shapes { get {
throw new NotImplementedException();
}
}
}
Robert C. Martin, too, thinks the shapes or at least their coordinates are special:
I want to know that the coordinates of the midpoint of the square are being calculated properly. I also want to ensure that the value of the midpoint is set by taking the average of the four corners. So I’m very interested in the calculation of the coordinates of those four corners.
However he does not derive from that the need for an explicit representation which can be tested individually. Instead he’s testing coordinate generation through the bottleneck of his algorithm’s root function interpolate() by letting a clever contraption accumulate coordinates in a string, e.g.

I prefer to make things more explicit. If there’s an important concept hidden in a problem it should be represented by a module (function, class, library etc.). That’s a form of documentation of my understanding and avoids the accumulation of concepts into a monolith.
Shapes and the shape hierarchy are no detail of my solution. Sure, the user does not need to know about them. But any fellow developers should. And since considerable testing is needed to get these aspects right, that should not require any test wizardry.
So much for structures I’m able to glean from the problem description. But what about the functionality?
Behavior
The overall functionality is to fill a matrix with values. That’s what Interpolate() represents to the user. But how does interpolation work? Is it a process with distinct steps or different aspects? Sure it is. Not much creativity is needed to come up with at least two.
- The vertex coordinates for each square and diamond need to be determined. That’s what is represented by the shapes and the shape hierarchy.
- And then for each shape the center cell’s value has to be calculated.
I don’t need TDD to stumble across this. It’s there in the algorithm’s description. So why not represent it explicitly in the code right from the start? Both aspects are not surprising details but should lead to consciously designed modules. No refactoring needed to arrive at them. They can easily be tested separately.
The ShapeHierarchy with its Shapes property stands for the first aspect. The second can be encapsulated in a Calculator, e.g.
class Calculator {
public static float Process(float[] values) {
throw new NotImplementedException();
}
}
But wait, what does calculation mean? It’s averaging the values and then adding some random jitter to the result. It’s this transformation which depends on the parameters passed to Interpolate() for creating randomness. That should show in the definition of Calculator:
class Calculator {
readonly float offset;
readonly float amplitude;
readonly Func<float> randomValue;
public Calculator(float offset, float amplitude, Func<float> randomValue) {
this.offset = offset;
this.amplitude = amplitude;
this.randomValue = randomValue;
}
public float Process(float[] values) {
throw new NotImplementedException();
}
}
Summary
Analysis is about understanding a problem. Understanding is represented by examples and modules which describe a „surface“, the contract. Then the examples get translated into tests for these modules.
Design is about finding a solution to the problem based on the understanding. A solution is described by internal modules representing behavior and data. A solution does not contain any logic. It’s declarative. It tells what needs to be done, not how.
The solution design is like a map. It’s rough, but still it’s useful to navigate through reality.
For the Diamond-Square algorithm the solution is
Break the terrain up into a hierarchy of squares and diamonds (shapes). For each shape calculate the value of its center from its vertexes. Fill the terrain with these values.
This is a declarative solution design given in prose. And I think it’s good clean code practice to represent its main problem domain concepts like shape, hierarchy, calculate, center, vertex, terrain in code as distinct modules. To wait for them to appear by doing TDD is to waste time and to make testing harder than needed.
- Part 1 – Analysis
- Part 2 – Design
- Part 3 – Implementation