

How to do TDD on a not so simple problem? Robert C. Martin has published a lesson on that tackling the Diamon-Square algorithm for terrain generation.
I think that’s a really interesting problem to consider as an exercise in software development to sharpen your skills. Today I presented it to a Clean Code training group and we had a lot of fun for a couple of hours.
Unfortunately I do not agree with how Robert C. Martin approached the solution. For one I find his statement
Don’t worry, it’s a very simple algorithm; and the linked article is extremely easy to read.
a bit misleading. It sounds as if this problem was on par with the usual code katas like „FizzBuzz“ or „WordWrap“. But in my experience it is not. It requires far more time to solve. Don’t try to cover it in a 90 minutes coding dojo with your programmer pals. You’ll give up frustrated.
But don’t worry. I won’t bother you with all the other reasons I don’t concur with Robert C. Martin. Instead let me just demonstrate a different perspective. If you find this an interesting contrast I will have accomplished what I want :-)
Analysis
Before you can code anything, you need to understand the problem. Understanding is the result of analysis. So the first step on my way to solving the Diamond-Square problem is to analyze the requirements, to look very closely. Whatever is already there can help me make coding easier. Any misunderstanding will create detours and waste.
Unfortunately there’s no product owner to explain the requirements to me and answer my questions. I’ve to drill my own way through the „specification“ given by Wikipedia.
Question no. 1 to be answered: How does the user of my solution want to use it? What’s the formal or syntactic contract supposed to look like?
Question no. 2 is: How does correct behavior of the System Under Development (SUD) look like? Is there a usage example?
In my view those two questions need to be answered in an unambiguous way. And the answers need to be written down. They even need to manifest in code. That’s also part of clean code.
Syntactic contract
How should the solution look on the outside? Let’s check what the specs are giving away:
The whole thing is revolving around a matrix, even a square matrix. A matrix of floating point values is created. The simplest way to express this in code would be a 2D array, e.g. float[,].
But not just any float array will do. First it has to be a square, then only certain sizes are allowed for the square; the length of a square – I call it its size – must be 2^n+1, e.g. 3, 5, 9, 257, but not 4 or 7 or 128. How can such a 2D array be enforced? How about a special type which always will lead to matrixes created correctly? It could pretty much look like a 2D float array, but a more constrained one. Here’s a simple usage example of such a type:
var size = new Terrain(3).Size;
Assert.AreEqual(9, size);
When creating such a matrix the user passes in n, not the size. That way the matrix can calculate the proper size.
Also I read that matrixes to be filled by the algorithm always start out with the corner cells set to initial values. Why not make that clear by adding constructor parameters?
var t = new Terrain(3, 1.0f, 2.0f, 3.0f, 4.0f);
Assert.AreEqual(1.0f, t[0, 0]);
Assert.AreEqual(2.0f, t[0, t.Size-1]);
Assert.AreEqual(3.0f, t[t.Size-1, t.Size-1]);
Assert.AreEqual(4.0f, t[t.Size-1, 0]);
In the end of course the terrain should be available as a plain float array for further processing by other code. The dependency on the special array-like type Terrain should be limited. A user needs a way to turn the matrix into an ordinary float array:
var t = new Terrain(1);
var m = t.ToArray();
Assert.IsTrue(m.GetLength(0) == m.GetLength(1));
Assert.AreEqual(t.Size, m.GetLength(0));
So much about the basic data structure the algorithm revolves around. But how to fill it with terrain height data? That sure is not a responsibility to be carried by the data type Terrain. Its sole purpose is keeping data in a consistent way.
Another module is needed. One that does all the necessary processing. An initialized Terrain will be its input. And in the end this Terrain is filled according to the algorithmic rules. A static method will do, I guess:
var t = new Terrain(1, 1.0f, 2.0f, 3.0f, 4.0f);
TerrainGenerator.Interpolate(t);
Assert.AreEqual(1.0f, t[0, 0]);
...
The values of the corner cells won’t be changed by the interpolation. The above test thus will be green. But what about the other cells. Their values will be calculated, that’s what the algorithm is about. It states that each cell’s value is the average of the values of some „surrounding“ cells plus a random value. For the above 3×3 terrain this would mean for the center cell t[1,1]: (1.0 + 2.0 + 3.0 + 4.0) / 4 + randomValue or 2.5 + randomValue.
To check for a correct calculation thus is not as simple as Assert.AreEqual(2.5f, t[1,1]). It probably would fail mostly because I cannot expect the random value to be 0.0 all the time. That would be against the definition of randomness ;-)
[the_ad_group id=“15″]
Semantic contract
So far the contract definition pretty much is about the syntax of the solution, its static surface: which classes should there be with which functions.
public class Terrain {
public Terrain(int n) {...}
public Terrain(int n, float leftTop, float rightTop, float rightBottom, float leftBottom) {...}
public int Size => matrix.GetLength(0);
public float this[int y, int x] { get; set; }
public float[,] ToArray() { ... }
}
public class TerrainGenerator {
public static void Interpolate(Terrain terrain) {...}
}
The contract defines how the solution can be used, e.g.
var t = new Terrain(10, 134.5f, 200.0f, 10.5f, 420.5);
TerrainGenerator.Interpolate(t);
var matrix = t.ToArray();
Nothing much can go wrong now. This makes very explicit what the requirements describe.
But what’s the behavior supposed to look like? t is only input to Interpolate(). What’s the output? To expect the corners to be initialized is not much of an expectation. That’s trivial and hardly needs testing. I’m talking about all the other cell values in a Terrain matrix.
As explained above they get calculated. But Interpolate() is not a pure function. Calling it multiple times with the same input won’t produce the same output due to the involvement of randomness.
That, too, is an aspect of the solution that needs to be explicitly expressed, I’d say. Without making the influence of randomness visible to the outside the solution will not be easily testable.
The least would be to inject into the solution a source of random values. Then it can be replaced for testing purposes if needed. But what’s the range the random values should be in? Wikipedia does not make any statement on this. But Robert C. Martin suggests two more values: an offset and an amplitude. If I understand him correctly this would mean a cell’s value should be calculated like this:
cell value = average +
offset +
random value in the range from -amplitude to +amplitude
Or to further separate the aspects:
cell value = average +
offset +
amplitude * random value in range from -1 to +1
Setting offset and amplitude to 0.0 would switch off random variations of averages.
To me these additions make sense. If a terrain is supposed to be made up of values in a certain range, then random values cannot just be between 0 and 1 as they usually are provided by random number generators. They need to be in the ball park of the initial values or whatever the user wants.
This leads to another modification of the contract:
void Interpolate(Terrain terrain,
float offset, float amplitude,
Func<float> randomValue)
Now the user can control the randomness or the „jitter“ of the interpolated values. This is great for testing purposes! And it makes an essential part of the algorithm obvious.
For convenience sake, though, an overloaded function can be defined which does not take a function for random value creation but provides a default internally. That’s for production use:
TerrainGenerator.Interpolate(t, 200.0f, 50.0f)
But during tests the parameter injection will come in handy. It will be easier to provide examples for the semantic contract.
The semantic contract is about input-output relations. Which input leads to which output? Possibly some resources also might be involved like in-memory data or a file or the printer. The overall change of data during transformation is what’s perceived by the user as the behavior of the software:
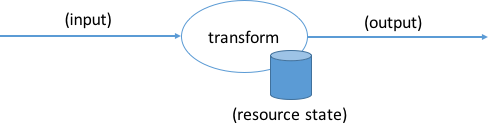
Or with the resource state extracted from the transformation and added to the data flow:
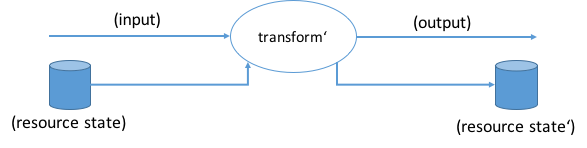
transform() is stateful, transform'() is stateless, i.e. a pure function.
Semantic contracts define the input data plus the resource state before the transformation and the output data plus the resource state after the transformation.
Are there any examples of Diamond-Square behavior in the specification? Unfortunately not. I have to come up with sample inputs and outputs myself, it seems.
No, wait, Robert C. Martin provided an example. For a 5×5 matrix with all corner cells set to 0.0 as the initial value, an offset of 4.0 and an amplitude of 2.0, plus all random values being 1.0.
[This] simply turns off the randomness, and uses the absolute values of the random amplitude instead.
The effect of this is that 4+2*1=6 will be added to all averages calculated. The resulting terrain looks like this in his test code:

Great! Thanks for doing all the calculations. It’s tedious.
But, alas, this does not prove anything about my own understanding. I should come up with an example myself. Bummer :-(
I could pick up pen and paper and do the calculations in my head – but why not put Excel to some good use? Here’s my first example, just plain averages (no offset, no amplitude, no randomness):
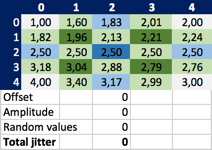
Still though, I don’t know whether that’s correct. I just carefully tried to translate the calculation rules from the algorithm description into Excel formulas. See how each cell refers to other cells to pick the values to average (and then add the random jitter):
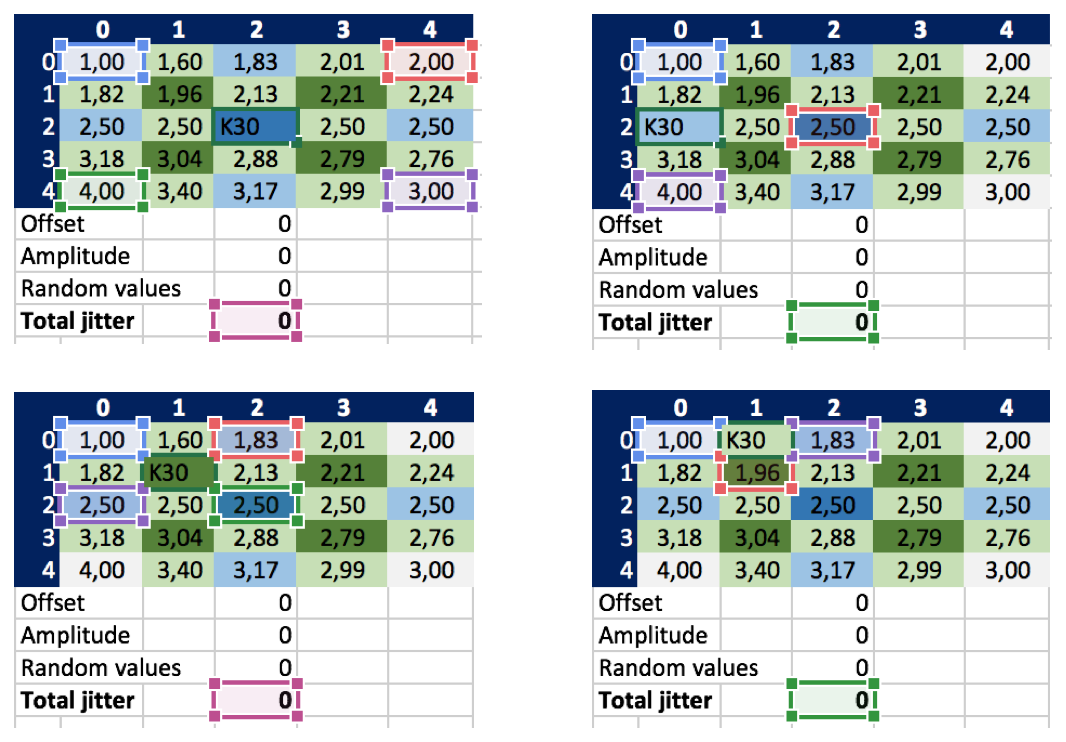
This is one of the challenges of this problem: to come up with correct examples.
But now that I have set up Excel, why not vary the data a bit? Here are the expected results for some other initial data and jitter:
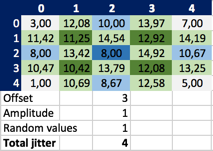
And now that I’m at it, why not start with the same data as Robert C. Martin?
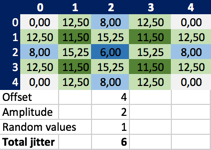
Hm… strange… my results look different from his. Why’s that? Take cell (1,1) for example: his value is 8.5, mine is 11,5. According to the specs the source cells to pull the values from for the average are these:
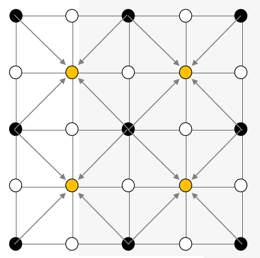
In Robert C. Martin’s matrix those values are 0.0, 8.0, 6.0, 8.0 with an average of 5.5. If I add the constant jitter of 6 to this I arrive at 11,5, but his value is 8.5.
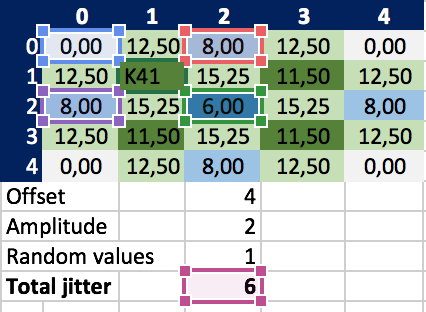
Strange. Who’s wrong, who’s right? Without knowing how he did it, I don’t know. I believe I applied the rules correctly.
Anyway, that’s a couple of examples I can start with. I should translate them into automated acceptance tests. Here’s how they look:
[Test]
public void Run_with_constant_jitter()
{
var t = new Terrain(2, 3.0f, 7.0f, 5.0f, 1.0f);
TerrainGenerator.Interpolate(t, 3.0f, 1.0f, () => 1.0f);
Assert_matrix_equality(new float[,] {
{ 3.00f, 12.08f, 10.00f, 13.97f, 7.00f} ,
{11.42f, 11.25f, 14.54f, 12.92f, 14.19f} ,
{ 8.00f, 13.42f, 8.00f, 14.92f, 10.67f} ,
{10.47f, 10.42f, 13.79f, 12.08f, 13.25f} ,
{ 1.00f, 10.69f, 8.67f, 12.58f, 5.00f}
}, t.ToArray());
}
They are simple, but typing in the expected matrix values is no fun :-( You’ve to be very careful to not introduce subtle mistakes.
Assert_matrix_equality() is a small helper method to compare the floating point values of the cells using a delta. The test framework’s Assert.AreEqual() does not allow for that when throwing arrays at it.
A test station for manual tests
Analysis could be complete now. I guess I understand how to calculate terrains using the Diamond-Square algorithm. I even can generate all kinds of examples for automated tests. They only suffer from one flaw: they are small. Setting up an Excel sheet for matrixes larger than 5×5 is prohibitive. So what about examples of size 9×9 or even 1025×1025?
There won’t be any. Sorry. That’s one of the reasons Robert C. Martin picked the algorithm for his TDD lesson. You cannot exhaustively check the result of the solution using examples. You need to find another way to gain confidence in your code. But that’s a matter of the phases after analysis.
So how could I check the correctness or rather „fitness“ of larger terrains? There’s no way I can do that precisely, i.e. by cell value, but I can at least check the overall visual impression of a terrain. In the end terrains are generated to be looked at, anyway. I don’t care for values but for visual appeal :-) Do the terrains look realistic or at least interesting?
To easily check that I set up a special test station for the algorithm. It generates terrains based on manually entered input values and shows them as a bitmap:
public static void Main(string[] args)
{
var n = int.Parse(Get_input("n in 2^n+1 for size [8]: ", "8"));
var tl = float.Parse(Get_input("Top left [100]: ", "100"));
var tr = float.Parse(Get_input("Top right [200]: ", "200"));
var br = float.Parse(Get_input("Bottom right [50]: ", "50"));
var bl = float.Parse(Get_input("Buttom left [150]: ", "150"));
var offset = float.Parse(Get_input("Offset [0]: ", "0"));
var amp = float.Parse(Get_input("Amplitude [10]: ", "10"));
var t = new Terrain(n, tl, tr, br, bl);
TerrainGenerator.Interpolate(t, offset, amp);
var hmp = new Heatmap(t.ToArray());
hmp.ToBitmap().Save($"terrain.png", System.Drawing.Imaging.ImageFormat.Png);
System.Diagnostics.Process.Start("terrain.png");
}
For the transformation of a floating point array into a bitmap I have to create a small mapper (Heatmap), though. It translates the terrain data into rainbow colors. But the effort for this is compensated by the ease with which I can check terrain generations at any time.
Get_input() reads some data from the console. The second parameter is the default value in case the user just presses ENTER.
Setting up such a test station might look like too much for such a small problem. But at least I would really like to see the terrains that get produced, not just floating point arrays. Since I don’t know graphics frameworks to render float arrays, I’m doing the translation myself.
Summary
Analysis is not just a mental exercise. Its results should be documented – as tests. Examples plus function signatures are concrete evidence of understanding. They should be manifested in code.
Such acceptance tests do not hint at any implementation, though. They don’t need to be incremental in any way. Hence you can expect them to stay red for quite a while.
But as soon as they turn green, you know you’re done :-)
In addition a test station for manual tests provides a means to make the solution more tangible in isolation. With it tests can be run by anybody.
However, doing the analysis in this way does not only result in tests which help stave off regressions. It helps structuring the solution. The specs don’t talk about functions or classes. But careful reading provides information on what should be tested. And that leads to a certain structure. Different aspects get expressed differently: a data structure with certain properties becomes a class, behavior of some kind becomes a function, dependencies on resources are made explicit.
To me that’s clean coding right from the start.
- Part 1 – Analysis
- Part 2 – Design
- Part 3 – Implementation