
Designing software with layers is common – and broken. It’s broken for two reasons:
- Layers suggest some form of abstraction; but layering very fundamentally is not about abstraction.
- Layering relies on functional dependencies which are hard to test and make software difficult to understand and evolve.
No Abstraction with Layers
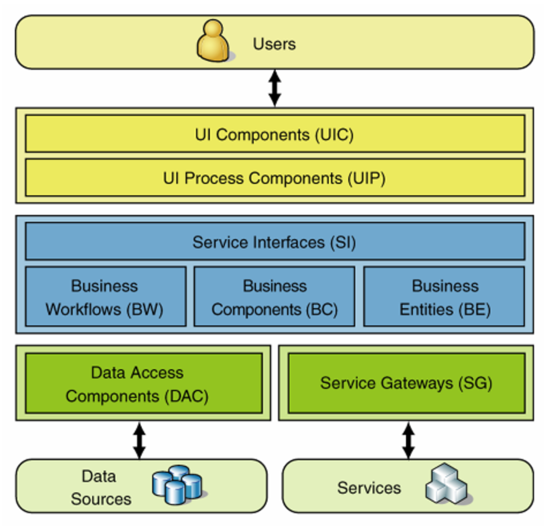
Take this layered design:
and compare it to these layers:
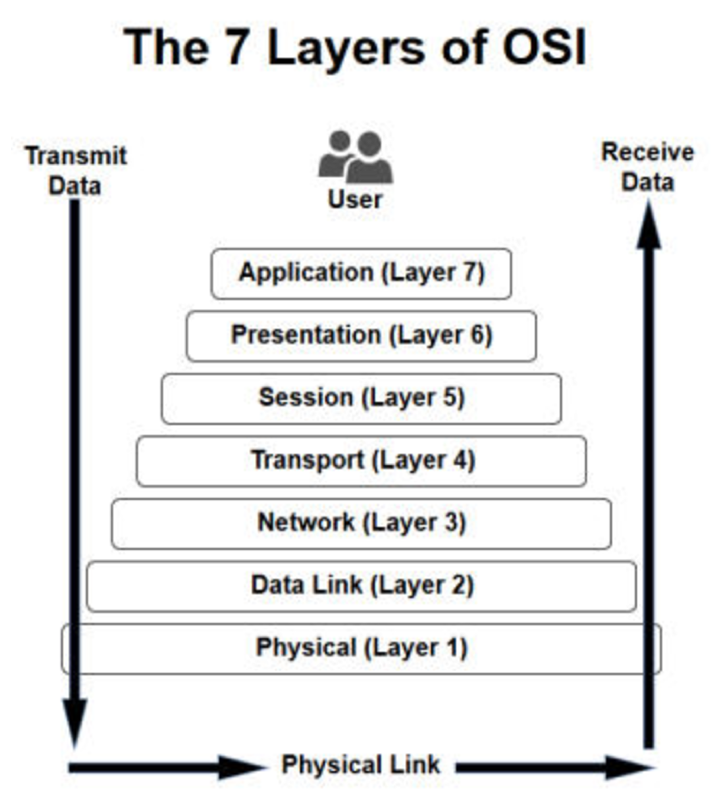
Do you see the difference?
Even though Scott Hanselman thinks he’s giving a „little reminder about layers of abstraction“, he’s not. Doing some UI stuff is not on a higher level of abstraction than doing some business stuff, which is not on a higher level of abstraction than doing data access stuff. UI and business and data access are just different stuff on the same level of abstraction.
Asking your mom for some bacon and toast and butter and salad is not on a higher level of abstraction than putting these ingredients together in a sandwich.
But a recipe is on a different level of abstraction! And that’s the point about recipes. They provide overview of what needs to be done: get ingredients, put them together in a certain way. Whether you ask mom for the ingredients or buy them at a grocery store yourself, that’s a detail. Whether you put them together yourself, ask your sister or let a machine do it, that’s a detail, too. Getting and putting together are just two tasks which combined form a whole.
The recipe represents the whole „Make sandwich“ on a high level of abstraction, and asking your mom and doing it yourself is the whole on a low level of abstraction.
Such differentiation between levels of abstraction is what the OSI layers are about. Each layer is describing the same: data transfer. But the application layer does that on a high level of abstraction and the network layer does it on a low level of abstraction.
It’s extraordinarily deplorable that the term „layer“ got used in both models. This has caused much confusion. And it has added value to the layered software design pattern which it does not deserve.
Abstraction with Strata
What to do about the term „layer“ then? I suggest to keep it but only use it in one kind of model. Let’s keep it for the layered design pattern. It’s more widely known today than the OSI layer model.
But what to call the OSI layers? I suggest to call them strata (singular: stratum).
I take this term from Abelson/Sussman who use it in their paper „Lisp: A Language for Stratified Design“.
Where layers are levels of equal abstraction in a software, strata are levels of different abstraction. „The 7 Layers of OSI“ then become „The 7 Strata of OSI“.
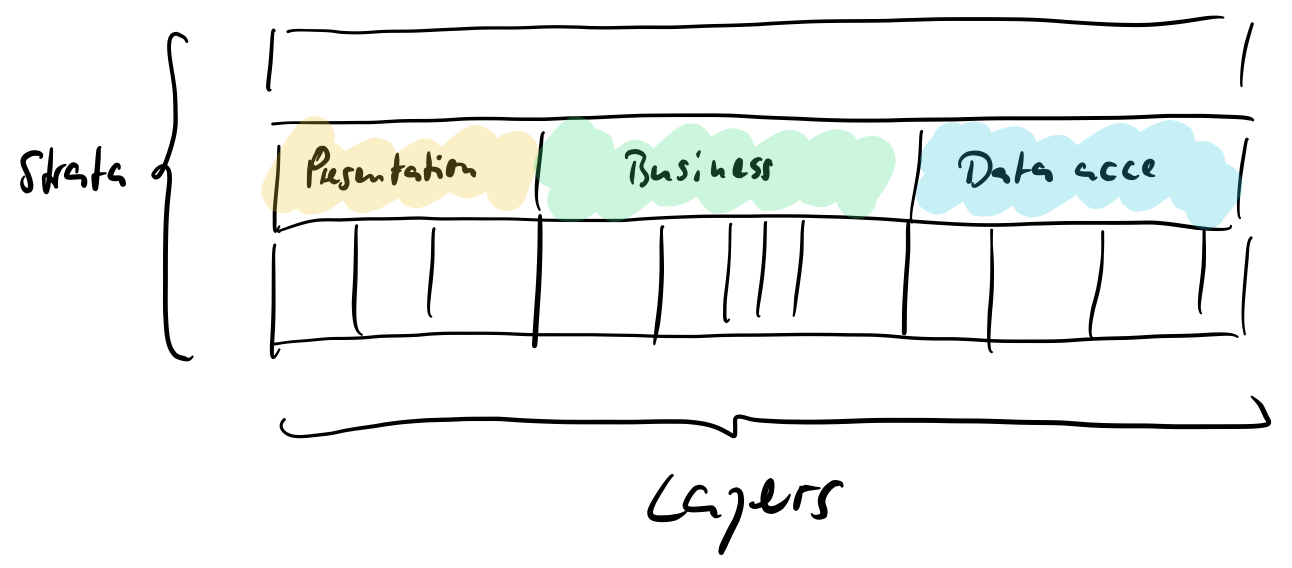
„Layer“ of course is not a bad term. It’s useful – as long as it has a very specific meaning. Since that’s the case now we can use both „layer“ and „stratum“ to talk meaningfully about software design. Both even go very well together in the same picture:
And not only Abelson/Sussman are talking about the power of abstraction. Alan Kay, the father of the term „object orientation“, does too. However he does so in a slightly different way. Instead of „stratum“ he uses the term „language“ or „domain specific language“ or „problem oriented language“.
But in fact it’s all the same: The basic structure of software should consist of code on distinct levels of abstraction. That’s not the case if you follow just the layered design pattern. You have to start thinking in a different dimension. You have to explicitly design strata orthogonally to layers.
Functional Dependencies are Hard to Test
Since different layers do different things they all need to work together to accomplish the whole task. Tasks are represented as cross-cuts across several layers.
The way to do that with layers is to make them know each other, to even functionally depend on each other. A higher layer calls a lower layer, a lower layer calls an even lower layer.
Sounds normal. But also sounds hard to evolve and hard to test. That’s why principles like Inversion of Control (IoC) and Dependency Inversion (DI) and tools like dependency injection containers and mock frameworks were invented.
However, even though a higher layer now does only depend on an abstraction instead of an implementation at design time, it needs an implementation at runtime. The dependency might be defused somewhat but it’s essentially still there. Testing now might be easier – but not really easy. And reasoning about the code is still difficult because nowhere the whole is visible. Looking at one layer only reveals some connection to another layer. What has been done before within the scope of a task, what will be done beyond the next layer…? To answer those questions you have to jump around in the code or even debug it. The whole which several layers form together has no clear representation.
And then: why should a layer depend on another anyway? Why should some code responsible for doing UI stuff be concerned about business stuff? Why should the UI know the business and control it through request/response calls? Or why should the business know how to fetch/store data? Why should it be concerned with data management at all? Its purpose is to work with data and produce results, that’s all. Any knowledge of how and when to access some data store it none of the business of the business functionality.
Functional dependencies – doing one thing and then waiting for some other party to deliver something so you can continue – are simply a poor form of organising work. That’s true for industrial production, work in an office, and in software.
Layered Design – An Example
To make the distinction between layers and strata more tangible for you, let me show you two solutions to the same small problem:
A user enters a one line text through the console and the program determines the number of words in the text. But not all words count! Some stop words defined in the file „stopwords.txt“ should be ignored.
That’s a problem which can easily be solved with a layered software design:
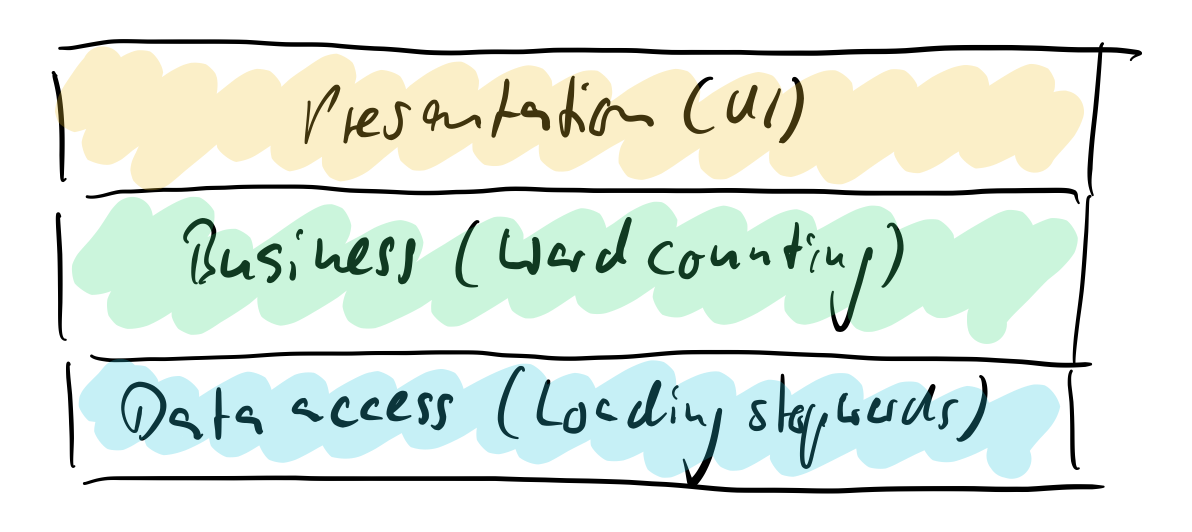
In code this looks like follows (for the whole code at once see here). Please forgive me to not have applied IoC. But I wanted to keep the implementation to the point of layers. IoC does not change the structure fundamentally. The dependencies remain, albeit somewhat mitigated.
public static void Main(string[] args) {
var data = new DataLayer();
var business = new BusinessLayer(data);
var presentation = new PresentationLayer(business);
presentation.Show();
}
The dependencies are clearly visible as objects being injected from bottom to top layer. That’s cute in this case – but it gets ugly once we start looking into the layers and/or dependency hierarchies grow.
Here’s the UI doing its work:
class PresentationLayer {
readonly BusinessLayer business;
public PresentationLayer(BusinessLayer business) {
this.business = business;
}
public void Show() {
Console.Write("Text: ");
var text = Console.ReadLine();
var n = this.business.Count_words(text);
Console.WriteLine($"Number of words: {n} ");
}
}
Although Show() might look normal to you, please try to see the fundamental problem: It’s difficult to test just the presentation logic.
Sure, the presentation logic in this case is trivial. But if you imagine a bigger problem with a more complicated solution the design stays the same and the logic is difficult to test.
How do you check if
Console.Write("Text: ");
var text = Console.ReadLine();
is doing its job correctly?
How do you check if
Console.WriteLine($"Number of words: {n} ");
is doing its job correctly?
- You cannot check both quite different parts of the presentation logic independent of each other.
- You cannot check both parts independent of some kind of business logic, be that the real thing or some mock implementation.
And on top of that: Why should the presentation know about this business stuff in the first place? The purpose of the presentation layer, the UI is to interact with the user, i.e. ask the user for data and her wishes and present data to the user. That’s all.
The same goes for the business layer:
class BusinessLayer {
readonly DataLayer data;
public BusinessLayer(DataLayer data) {
this.data = data;
}
public int Count_words(string text) {
var words = Extract_words(text);
return words.Length;
}
private string[] Extract_words(string text) {
var words = text.Split(new[] { ' ', '\t', '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
return Remove_stopwords(words);
}
private string[] Remove_stopwords(string[] words) {
var stopwords = this.data.Load_stopwords();
words = words.Except(stopwords).ToArray();
return words;
}
}
How do you test word extraction logic in isolation? You cannot. Layering has even been refined here. The business layer itself consists of yet more sub-layers depending on each other. What a nightmare!
This all is hard to test (even with IoC & dependency injection). And it’s hard to understand in the first place. The need for a dependency diagram is very high!
The class dependencies might be simple:
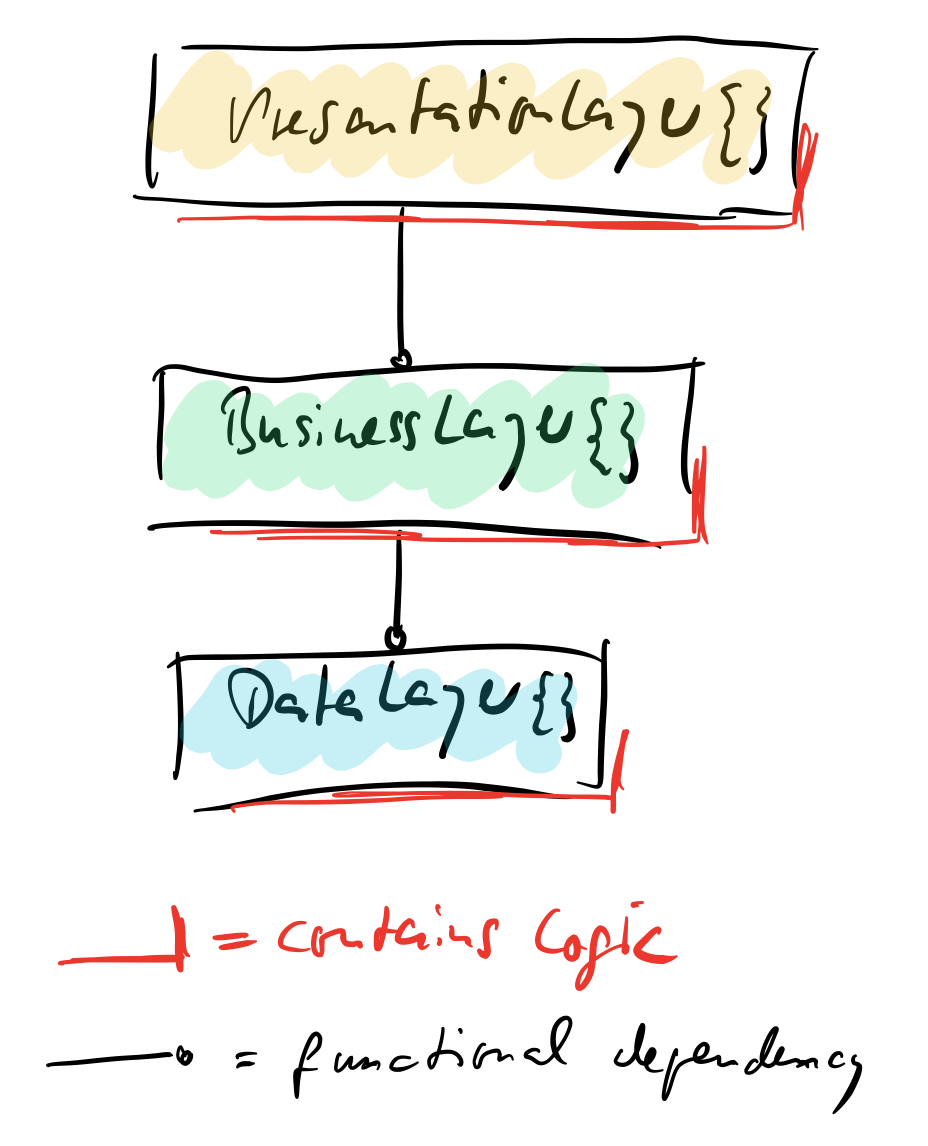
But look closer! There are so many functions depending on each other, each containing logic calling logic in yet other functions.
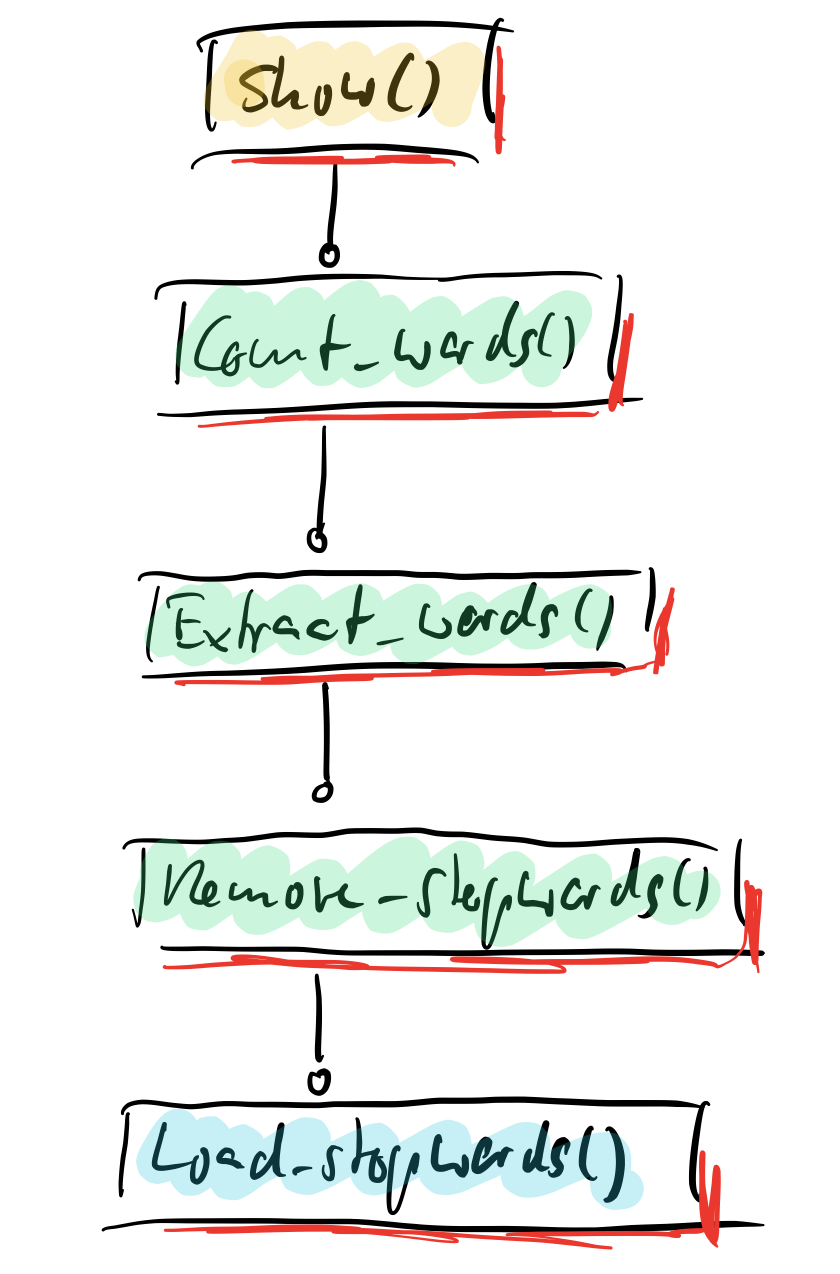
Again: That’s a very common structure for software. Nothing out of the ordinary here. Look at your project’s code. It’s the same – only worse, because it contains 10,000 times more lines of code to solve a massively more complicated problem.
But that means, the problems of the layered design are also much, much bigger for you.
Stratified Design – An Example
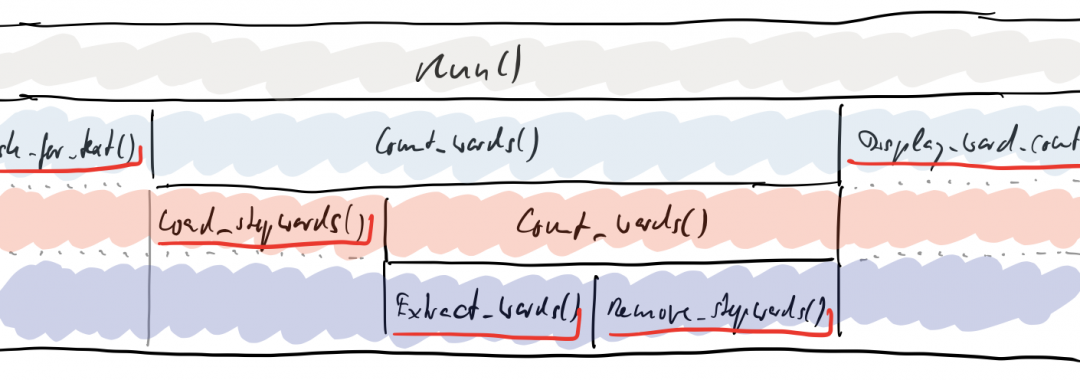
A stratified design for the same problem of course will consist of the same basic functional aspects – e.g. loading stop words from a file, presenting the result to the user, removing stop words from the list of words in the text. But a stratified design will arrange those aspects differently. This will become obvious already at the entry point of the application:
public static void Main(string[] args) {
var data = new Data();
var business = new Business();
var presentation = new Presentation();
var app = new App(presentation, business, data);
app.Run();
}
Firstly, the classes of the layers don’t know each other anymore. No dependency injection between them. Business logic no longer cares about loading stop words.
Secondly, there is a new class App{}. It represents the top stratum of the application, it stands for the whole of what needs to be done. The sole purpose of App{} is to integrate the layers into this whole.
App.Run() thus represents everything that happens – on the highest possible level of abstraction. The overall behaviour is expressed as one verb.
Now let’s drill down! And a drill down it is, because we’re talking about strata not layers. There is no real drill down into layers, only maybe a drill through.
If Run() is about everything, then what’s inside of the function, too, is about everything – just on a little lower level of abstraction:
public void Run() {
var text = presentation.Ask_for_text();
var n = Count_words(text);
presentation.Display_word_count(n);
}
Ah, now you see: „everything“ means asking for a text, then counting words in the text, and finally presenting the number of words to the user.
In the layered design there’s nowhere you have such an overview of the whole process.
But, wait, there’s more! What does „counting words“ mean? How is it done? You can see all of it on a high level of abstraction with another drill down:
private int Count_words(string text) {
var stopwords = data.Load_stopwords();
return Business.Count_words(text, stopwords);
}
Ah, now you see: the „everything“ of „counting words“ means first loading stop words and then doing the actual word count by taking the stop words into account.
Since Ask_for_text() and Display_word_count() contain only logic
public string Ask_for_text() {
Console.Write("Text: ");
return Console.ReadLine();
}
public void Display_word_count(int n) {
Console.WriteLine($"Number of words: {n} ");
}
they get carried over into this lower level of abstraction. On stratum #3 the whole of accomplishing the task consist of asking for a text, loading stop words, counting the words by applying the stop words, and in the end displaying the result.
And what about the core domain „counting words“ in Business{}? Let’s drill down again:
class Business {
public static int Count_words(string text, string[] stopwords) {
var words = Extract_words(text);
words = Remove_stopwords(words, stopwords);
return words.Count();
}
private static string[] Extract_words(string text) {
return text.Split(new[] { ' ', '\t', '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
}
private static string[] Remove_stopwords(string[] words, string[] stopwords) {
return words.Except(stopwords).ToArray();
}
}
See how Count_words{} does not contain any logic? There’s nothing that could go wrong here. Nothing needs to be tested. It’s just integration again. No functional dependencies.
You immediately get an overview of what „counting words“ means. The whole is visible at a glance: first, actually get the words from the text, then remove from them the stop words, finally count the remaining words.
What needs to be done is not deeply nested but laid out sequentially.
Check out the class design:
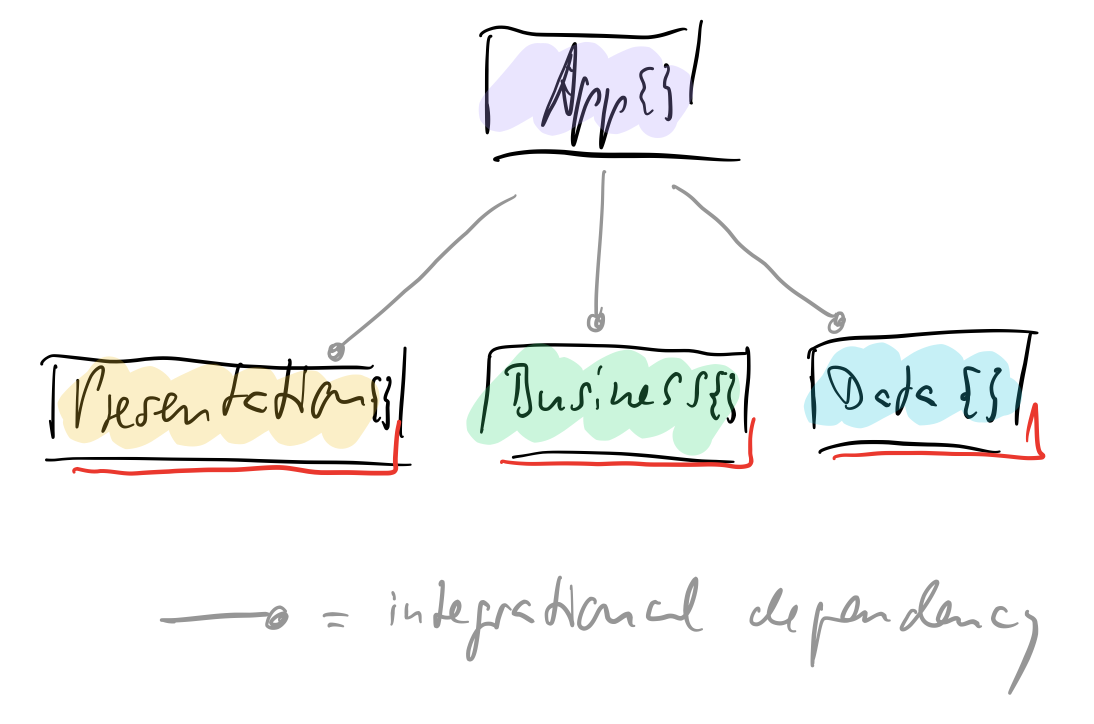
It makes even more clear how independent the functional aspects of the solutions are. Only App{} knows the workhorse classes – but App{} does not contain any logic. It’s only there to integrate the parts into a whole. But that’s a very important task! It’s a responsibility of its own to be separated from actually doing stuff like processing data or loading data.
But please note: The relationship between App{} and Presentation{} etc. is not functional! There is no logic in App{} which uses logic in Presentation{} etc. The relationship thus is purely „integrational“.
And then there is the hierarchy of functions:
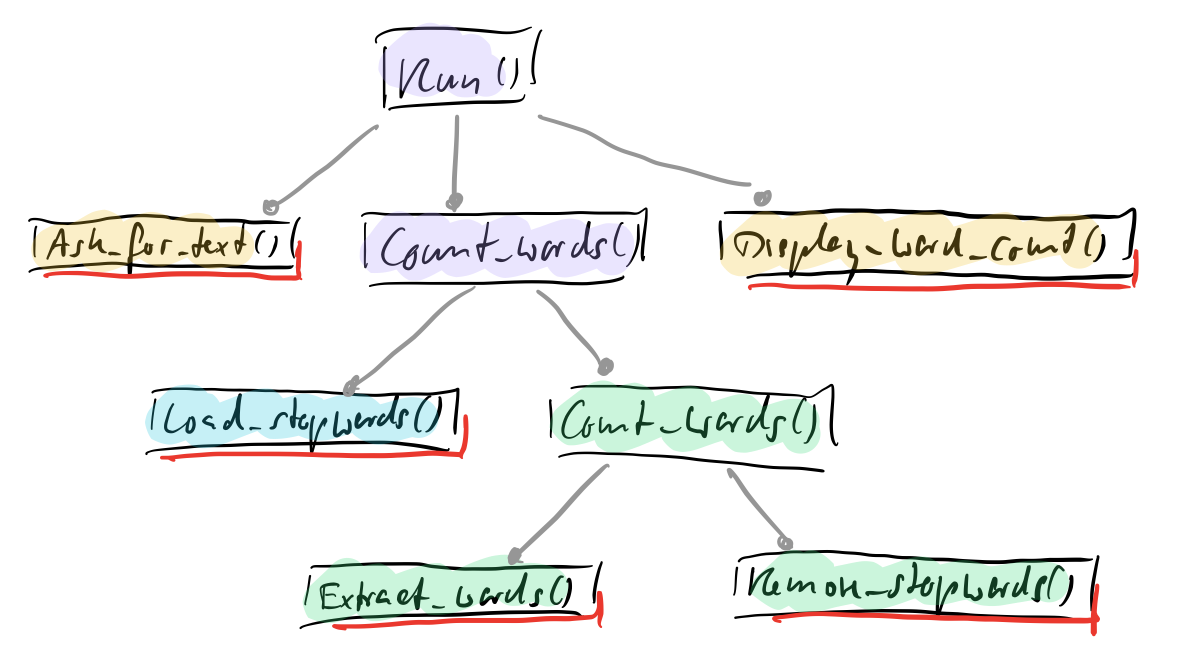
This diagram shows the nesting in a away so you can see the strata. Each function is sitting on the level where it’s used. That way lower strata are just sparsely populated. Some functions simply represent vocabulary relevant on several levels of abstraction.
Maybe this becomes more clear when I show you the strata explicitly:
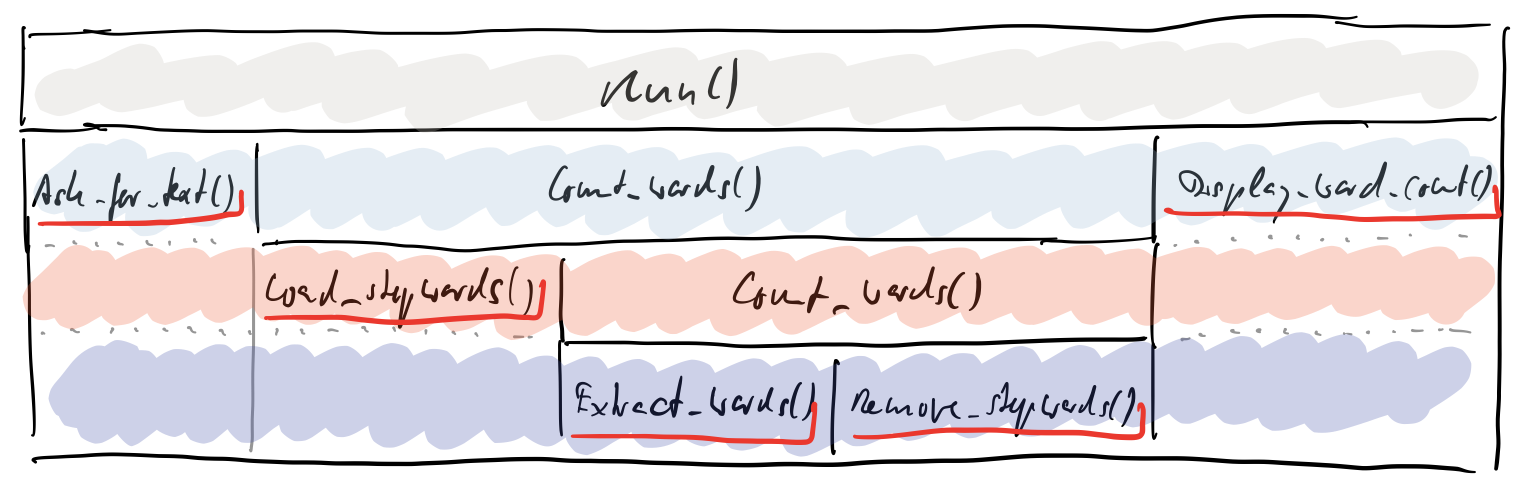
But do you see how logic only resides in the leafs of the call tree? Let me move around the functions a little bit:
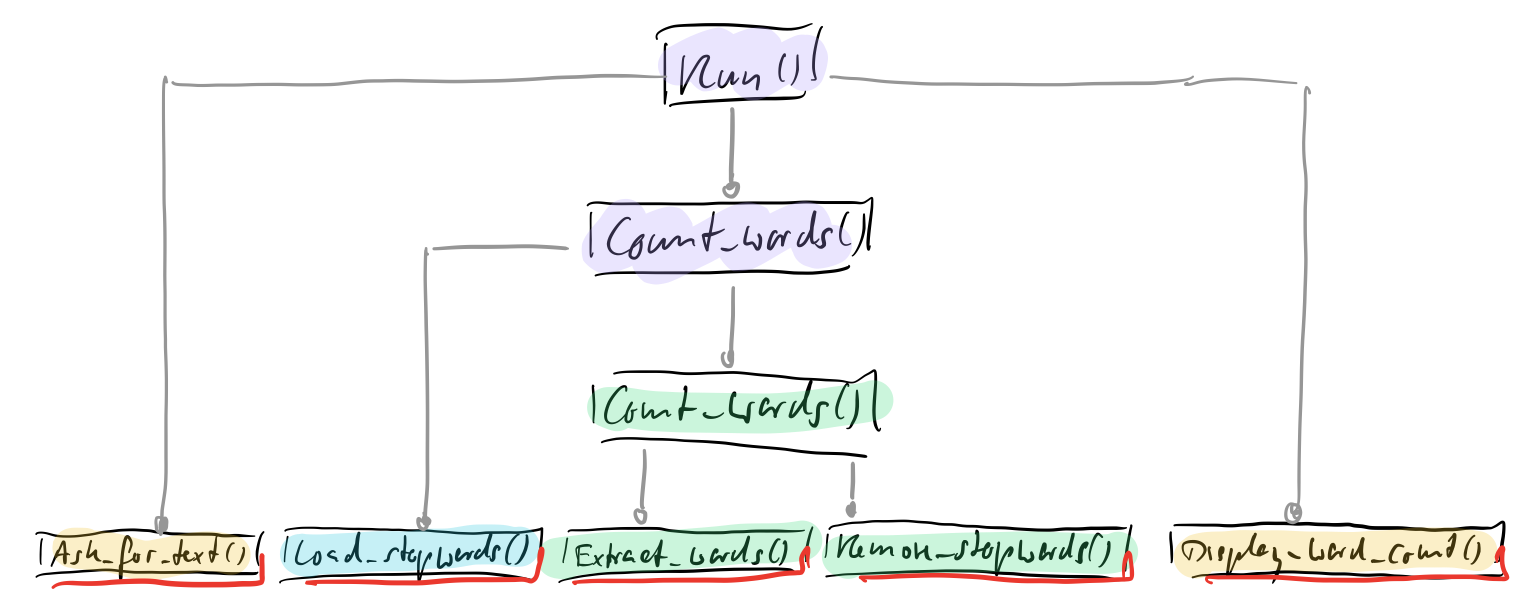
I call those functions with just logic in them and without any dependencies operations. The other ones without logic but with integrational dependencies are integrations.
The overarching principle here is the Integration Operation Segregation Principle (IOSP). A function either integrates or operates, it either only calls other functions or it does not call other functions but contains only logic.
Run(), Count_words() are integrations, Ask_for_text() or Extract_words() etc. are operations.
As you can imagine: Operations are easy to test. No functional dependencies! Integrations on the other hand, you might think, are not easy to test due to their dependencies – but they don’t need to be tested. There simply is nothing to test, no logic. If the functions an integration is integrating are correct, then the integration also is correct.
Of course I’m assuming it’s easy to check by review whether an integration actually is calling the right functions in the right sequence. But experience tells me, that’s most often the case.
That said, you’re free to test integrations too, if you like. And of course integrations at the root or close to the root should be tested to see if the overall idea of how the whole is assembled from the parts is correct. I call that acceptance tests.
Check out the complete stratified source code. It’s only slightly longer than the layered code, but I find its readability is much higher. Especially the integration functions adhere very well to the Single Level of Abstraction (SLA) principle.
Also the functions are more to the point. They are following the Single Responsibility Principle (SRP) much more closely because they focus on either integration or operation.
Conclusion
Stratified design avoids the pitfalls of layered design:
- Strata are true abstractions, i.e. it’s easier to understand the code since details are properly hidden without sacrificing the big picture.
- Testability is high due to accumulation of logic in the leafs of a call tree.
Functional aspects are focused on their purpose and don’t need to be concerned with other functional aspects. This increases decoupling.
Stratified design is what the IODA Architecture is about. But stratified design is more general. It’s relevant in the small and in the large. You can apply it to the next kata you’re doing in a coding dojo.
Take the CSV Table-izer for example. The function in demand is a whole, it represents the top stratum on the highest level of abstraction. Now drill down and stay true to the IOSP. That’s all there is to stratified design. Design your own small domain languages. No DSL tools needed. Just come up with many verbs and some nouns on different levels of abstraction which you arrange in strata. You’ll help greatly the readability and testability of your code – and finally escape the dependency hell of layered design.